
number
int64 2
7.91k
| title
stringlengths 1
290
| body
stringlengths 0
228k
| state
stringclasses 2
values | created_at
timestamp[s]date 2020-04-14 18:18:51
2025-12-16 10:45:02
| updated_at
timestamp[s]date 2020-04-29 09:23:05
2025-12-16 19:34:46
| closed_at
timestamp[s]date 2020-04-29 09:23:05
2025-12-16 14:20:48
⌀ | url
stringlengths 48
51
| author
stringlengths 3
26
⌀ | comments_count
int64 0
70
| labels
listlengths 0
4
|
|---|---|---|---|---|---|---|---|---|---|---|
5,568
|
dataset.to_iterable_dataset() loses useful info like dataset features
|
### Describe the bug
Hello,
I like the new `to_iterable_dataset` feature but I noticed something that seems to be missing.
When using `to_iterable_dataset` to transform your map style dataset into iterable dataset, you lose valuable metadata like the features.
These metadata are useful if you want to interleave iterable datasets, cast columns etc.
### Steps to reproduce the bug
```python
dataset = load_dataset("lhoestq/demo1")["train"]
print(dataset.features)
# {'id': Value(dtype='string', id=None), 'package_name': Value(dtype='string', id=None), 'review': Value(dtype='string', id=None), 'date': Value(dtype='string', id=None), 'star': Value(dtype='int64', id=None), 'version_id': Value(dtype='int64', id=None)}
dataset = dataset.to_iterable_dataset()
print(dataset.features)
# None
```
### Expected behavior
Keep the relevant information
### Environment info
datasets==2.10.0
|
CLOSED
| 2023-02-23T13:45:33
| 2023-02-24T13:22:36
| 2023-02-24T13:22:36
|
https://github.com/huggingface/datasets/issues/5568
|
bruno-hays
| 3
|
[
"enhancement",
"good first issue"
] |
5,566
|
Directly reading parquet files in a s3 bucket from the load_dataset method
|
### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Your contribution
I am willing to help if there's anyway.
|
OPEN
| 2023-02-22T22:13:40
| 2023-02-23T11:03:29
| null |
https://github.com/huggingface/datasets/issues/5566
|
shamanez
| 1
|
[
"duplicate",
"enhancement"
] |
5,555
|
`.shuffle` throwing error `ValueError: Protocol not known: parent`
|
### Describe the bug
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [16], line 1
----> 1 train_dataset = train_dataset.shuffle()
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:551, in transmit_format.<locals>.wrapper(*args, **kwargs)
544 self_format = {
545 "type": self._format_type,
546 "format_kwargs": self._format_kwargs,
547 "columns": self._format_columns,
548 "output_all_columns": self._output_all_columns,
549 }
550 # apply actual function
--> 551 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
552 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
553 # re-apply format to the output
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/fingerprint.py:480, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
476 validate_fingerprint(kwargs[fingerprint_name])
478 # Call actual function
--> 480 out = func(self, *args, **kwargs)
482 # Update fingerprint of in-place transforms + update in-place history of transforms
484 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:3616, in Dataset.shuffle(self, seed, generator, keep_in_memory, load_from_cache_file, indices_cache_file_name, writer_batch_size, new_fingerprint)
3610 return self._new_dataset_with_indices(
3611 fingerprint=new_fingerprint, indices_cache_file_name=indices_cache_file_name
3612 )
3614 permutation = generator.permutation(len(self))
-> 3616 return self.select(
3617 indices=permutation,
3618 keep_in_memory=keep_in_memory,
3619 indices_cache_file_name=indices_cache_file_name if not keep_in_memory else None,
3620 writer_batch_size=writer_batch_size,
3621 new_fingerprint=new_fingerprint,
3622 )
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:551, in transmit_format.<locals>.wrapper(*args, **kwargs)
544 self_format = {
545 "type": self._format_type,
546 "format_kwargs": self._format_kwargs,
547 "columns": self._format_columns,
548 "output_all_columns": self._output_all_columns,
549 }
550 # apply actual function
--> 551 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
552 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
553 # re-apply format to the output
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/fingerprint.py:480, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
476 validate_fingerprint(kwargs[fingerprint_name])
478 # Call actual function
--> 480 out = func(self, *args, **kwargs)
482 # Update fingerprint of in-place transforms + update in-place history of transforms
484 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:3266, in Dataset.select(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
3263 return self._select_contiguous(start, length, new_fingerprint=new_fingerprint)
3265 # If not contiguous, we need to create a new indices mapping
-> 3266 return self._select_with_indices_mapping(
3267 indices,
3268 keep_in_memory=keep_in_memory,
3269 indices_cache_file_name=indices_cache_file_name,
3270 writer_batch_size=writer_batch_size,
3271 new_fingerprint=new_fingerprint,
3272 )
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:551, in transmit_format.<locals>.wrapper(*args, **kwargs)
544 self_format = {
545 "type": self._format_type,
546 "format_kwargs": self._format_kwargs,
547 "columns": self._format_columns,
548 "output_all_columns": self._output_all_columns,
549 }
550 # apply actual function
--> 551 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
552 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
553 # re-apply format to the output
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/fingerprint.py:480, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
476 validate_fingerprint(kwargs[fingerprint_name])
478 # Call actual function
--> 480 out = func(self, *args, **kwargs)
482 # Update fingerprint of in-place transforms + update in-place history of transforms
484 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_dataset.py:3389, in Dataset._select_with_indices_mapping(self, indices, keep_in_memory, indices_cache_file_name, writer_batch_size, new_fingerprint)
3387 logger.info(f"Caching indices mapping at {indices_cache_file_name}")
3388 tmp_file = tempfile.NamedTemporaryFile("wb", dir=os.path.dirname(indices_cache_file_name), delete=False)
-> 3389 writer = ArrowWriter(
3390 path=tmp_file.name, writer_batch_size=writer_batch_size, fingerprint=new_fingerprint, unit="indices"
3391 )
3393 indices = indices if isinstance(indices, list) else list(indices)
3395 size = len(self)
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/datasets/arrow_writer.py:315, in ArrowWriter.__init__(self, schema, features, path, stream, fingerprint, writer_batch_size, hash_salt, check_duplicates, disable_nullable, update_features, with_metadata, unit, embed_local_files, storage_options)
312 self._disable_nullable = disable_nullable
314 if stream is None:
--> 315 fs_token_paths = fsspec.get_fs_token_paths(path, storage_options=storage_options)
316 self._fs: fsspec.AbstractFileSystem = fs_token_paths[0]
317 self._path = (
318 fs_token_paths[2][0]
319 if not is_remote_filesystem(self._fs)
320 else self._fs.unstrip_protocol(fs_token_paths[2][0])
321 )
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/fsspec/core.py:593, in get_fs_token_paths(urlpath, mode, num, name_function, storage_options, protocol, expand)
591 else:
592 urlpath = stringify_path(urlpath)
--> 593 chain = _un_chain(urlpath, storage_options or {})
594 if len(chain) > 1:
595 inkwargs = {}
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/fsspec/core.py:330, in _un_chain(path, kwargs)
328 for bit in reversed(bits):
329 protocol = split_protocol(bit)[0] or "file"
--> 330 cls = get_filesystem_class(protocol)
331 extra_kwargs = cls._get_kwargs_from_urls(bit)
332 kws = kwargs.get(protocol, {})
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/fsspec/registry.py:240, in get_filesystem_class(protocol)
238 if protocol not in registry:
239 if protocol not in known_implementations:
--> 240 raise ValueError("Protocol not known: %s" % protocol)
241 bit = known_implementations[protocol]
242 try:
ValueError: Protocol not known: parent
```
This is what the `train_dataset` object looks like
```
Dataset({
features: ['label', 'input_ids', 'attention_mask'],
num_rows: 364166
})
```
### Steps to reproduce the bug
The `train_dataset` obj is created by concatenating two datasets
And then shuffle is called, but it throws the mentioned error.
### Expected behavior
Should shuffle the dataset properly.
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.15.0-1022-aws-x86_64-with-glibc2.31
- Python version: 3.9.13
- PyArrow version: 10.0.0
- Pandas version: 1.4.4
|
OPEN
| 2023-02-20T21:33:45
| 2023-02-27T09:23:34
| null |
https://github.com/huggingface/datasets/issues/5555
|
prabhakar267
| 4
|
[] |
5,548
|
Apply flake8-comprehensions to codebase
|
### Feature request
Apply ruff flake8 comprehension checks to codebase.
### Motivation
This should strictly improve the performance / readability of the codebase by removing unnecessary iteration, function calls, etc. This should generate better Python bytecode which should strictly improve performance.
I already applied this fixes to PyTorch and Sympy with little issue and have opened PRs to diffusers and transformers todo this as well.
### Your contribution
Making a PR.
|
CLOSED
| 2023-02-19T20:05:38
| 2023-02-23T13:59:41
| 2023-02-23T13:59:41
|
https://github.com/huggingface/datasets/issues/5548
|
Skylion007
| 0
|
[
"enhancement"
] |
5,546
|
Downloaded datasets do not cache at $HF_HOME
|
### Describe the bug
In the huggingface course (https://huggingface.co/course/chapter3/2?fw=pt) it said that if we set HF_HOME, downloaded datasets would be cached at specified address but it does not. downloaded models from checkpoint names are downloaded and cached at HF_HOME but this is not the case for datasets, they are still cached at ~/.cache/huggingface/datasets.
### Steps to reproduce the bug
Run the following code
```
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
```
it downloads and store dataset at ~/.cache/huggingface/datasets
### Expected behavior
to cache dataset at HF_HOME.
### Environment info
python 3.10.6
Kubuntu 22.04
HF_HOME located on a separate partition
|
CLOSED
| 2023-02-18T13:30:35
| 2023-07-24T14:22:43
| 2023-07-24T14:22:43
|
https://github.com/huggingface/datasets/issues/5546
|
ErfanMoosaviMonazzah
| 1
|
[] |
5,543
|
the pile datasets url seems to change back
|
### Describe the bug
in #3627, the host url of the pile dataset became `https://mystic.the-eye.eu`. Now the new url is broken, but `https://the-eye.eu` seems to work again.
### Steps to reproduce the bug
```python3
from datasets import load_dataset
dataset = load_dataset("bookcorpusopen")
```
shows
```python3
ConnectionError: Couldn't reach https://mystic.the-eye.eu/public/AI/pile_preliminary_components/books1.tar.gz (ProxyError(MaxRetryError("HTTPSConnectionPool(host='mystic.the-eye.eu', port=443): Max retries exceeded with url: /public/AI/pile_pr
eliminary_components/books1.tar.gz (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 504 Gateway Timeout')))")))
```
### Expected behavior
Downloading as normal.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.4.143.bsk.7-amd64-x86_64-with-glibc2.31
- Python version: 3.9.2
- PyArrow version: 6.0.1
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-17T08:40:11
| 2023-02-21T06:37:00
| 2023-02-20T08:41:33
|
https://github.com/huggingface/datasets/issues/5543
|
wjfwzzc
| 2
|
[] |
5,541
|
Flattening indices in selected datasets is extremely inefficient
|
### Describe the bug
If we perform a `select` (or `shuffle`, `train_test_split`, etc.) operation on a dataset , we end up with a dataset with an `indices_table`. Currently, flattening such dataset consumes a lot of memory and the resulting flat dataset contains ChunkedArrays with as many chunks as there are rows. This is extremely inefficient and slows down the operations on the flat dataset, e.g., saving/loading the dataset to disk becomes really slow.
Perhaps more importantly, loading the dataset back from disk basically loads the whole table into RAM, as it cannot take advantage of memory mapping.
### Steps to reproduce the bug
The following script reproduces the issue:
```python
import gc
import os
import psutil
import tempfile
import time
from datasets import Dataset
DATASET_SIZE = 5000000
def profile(func):
def wrapper(*args, **kwargs):
mem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
start = time.time()
# Run function here
out = func(*args, **kwargs)
end = time.time()
mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
print(f"{func.__name__} -- RAM memory used: {mem_after - mem_before} MB -- Total time: {end - start:.6f} s")
return out
return wrapper
def main():
ds = Dataset.from_list([{'col': i} for i in range(DATASET_SIZE)])
print(f"Num chunks for original ds: {ds.data['col'].num_chunks}")
with tempfile.TemporaryDirectory() as tmpdir:
path1 = os.path.join(tmpdir, 'ds1')
print("Original ds save/load")
profile(ds.save_to_disk)(path1)
ds_loaded = profile(Dataset.load_from_disk)(path1)
print(f"Num chunks for original ds after reloading: {ds_loaded.data['col'].num_chunks}")
print("")
ds_select = ds.select(reversed(range(len(ds))))
print(f"Num chunks for selected ds: {ds_select.data['col'].num_chunks}")
del ds
del ds_loaded
gc.collect()
# This would happen anyway when we call save_to_disk
ds_select = profile(ds_select.flatten_indices)()
print(f"Num chunks for selected ds after flattening: {ds_select.data['col'].num_chunks}")
print("")
path2 = os.path.join(tmpdir, 'ds2')
print("Selected ds save/load")
profile(ds_select.save_to_disk)(path2)
del ds_select
gc.collect()
ds_select_loaded = profile(Dataset.load_from_disk)(path2)
print(f"Num chunks for selected ds after reloading: {ds_select_loaded.data['col'].num_chunks}")
if __name__ == '__main__':
main()
```
Sample result:
```
Num chunks for original ds: 1
Original ds save/load
save_to_disk -- RAM memory used: 0.515625 MB -- Total time: 0.253888 s
load_from_disk -- RAM memory used: 42.765625 MB -- Total time: 0.015176 s
Num chunks for original ds after reloading: 5000
Num chunks for selected ds: 1
flatten_indices -- RAM memory used: 4852.609375 MB -- Total time: 46.116774 s
Num chunks for selected ds after flattening: 5000000
Selected ds save/load
save_to_disk -- RAM memory used: 1326.65625 MB -- Total time: 42.309825 s
load_from_disk -- RAM memory used: 2085.953125 MB -- Total time: 11.659137 s
Num chunks for selected ds after reloading: 5000000
```
### Expected behavior
Saving/loading the dataset should be much faster and consume almost no extra memory thanks to pyarrow memory mapping.
### Environment info
- `datasets` version: 2.9.1.dev0
- Platform: macOS-13.1-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-17T01:52:24
| 2023-02-22T13:15:20
| 2023-02-17T11:12:33
|
https://github.com/huggingface/datasets/issues/5541
|
marioga
| 3
|
[] |
5,539
|
IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number
|
### Describe the bug
When dataset contains a 0-dim tensor, formatting.py raises a following error and fails.
```bash
Traceback (most recent call last):
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 501, in format_row
return _unnest(formatted_batch)
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 137, in _unnest
return {key: array[0] for key, array in py_dict.items()}
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 137, in <dictcomp>
return {key: array[0] for key, array in py_dict.items()}
IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number
```
### Steps to reproduce the bug
Load whichever dataset and add transform method to add 0-dim tensor. Or create/find a dataset containing 0-dim tensor. E.g.
```python
from datasets import load_dataset
import torch
dataset = load_dataset("lambdalabs/pokemon-blip-captions", split='train')
def t(batch):
return {"test": torch.tensor(1)}
dataset.set_transform(t)
d_0 = dataset[0]
```
### Expected behavior
Extractor will correctly get a row from the dataset, even if it contains 0-dim tensor.
### Environment info
`datasets==2.8.0`, but it looks like it is also applicable to main branch version (as of 16th February)
|
CLOSED
| 2023-02-16T16:08:51
| 2023-02-22T10:30:30
| 2023-02-21T13:03:57
|
https://github.com/huggingface/datasets/issues/5539
|
aalbersk
| 4
|
[
"good first issue"
] |
5,538
|
load_dataset in seaborn is not working for me. getting this error.
|
TimeoutError Traceback (most recent call last)
~\anaconda3\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chunked=req.has_header('Transfer-encoding'))
~\anaconda3\lib\http\client.py in request(self, method, url, body, headers, encode_chunked)
1278 """Send a complete request to the server."""
-> 1279 self._send_request(method, url, body, headers, encode_chunked)
1280
~\anaconda3\lib\http\client.py in _send_request(self, method, url, body, headers, encode_chunked)
1324 body = _encode(body, 'body')
-> 1325 self.endheaders(body, encode_chunked=encode_chunked)
1326
~\anaconda3\lib\http\client.py in endheaders(self, message_body, encode_chunked)
1273 raise CannotSendHeader()
-> 1274 self._send_output(message_body, encode_chunked=encode_chunked)
1275
~\anaconda3\lib\http\client.py in _send_output(self, message_body, encode_chunked)
1033 del self._buffer[:]
-> 1034 self.send(msg)
1035
~\anaconda3\lib\http\client.py in send(self, data)
973 if self.auto_open:
--> 974 self.connect()
975 else:
~\anaconda3\lib\http\client.py in connect(self)
1440
-> 1441 super().connect()
1442
~\anaconda3\lib\http\client.py in connect(self)
944 """Connect to the host and port specified in __init__."""
--> 945 self.sock = self._create_connection(
946 (self.host,self.port), self.timeout, self.source_address)
~\anaconda3\lib\socket.py in create_connection(address, timeout, source_address)
843 try:
--> 844 raise err
845 finally:
~\anaconda3\lib\socket.py in create_connection(address, timeout, source_address)
831 sock.bind(source_address)
--> 832 sock.connect(sa)
833 # Break explicitly a reference cycle
TimeoutError: [WinError 10060] A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_12220/2927704185.py in <module>
1 import seaborn as sn
----> 2 iris = sn.load_dataset('iris')
~\anaconda3\lib\site-packages\seaborn\utils.py in load_dataset(name, cache, data_home, **kws)
594 if name not in get_dataset_names():
595 raise ValueError(f"'{name}' is not one of the example datasets.")
--> 596 urlretrieve(url, cache_path)
597 full_path = cache_path
598 else:
~\anaconda3\lib\urllib\request.py in urlretrieve(url, filename, reporthook, data)
237 url_type, path = _splittype(url)
238
--> 239 with contextlib.closing(urlopen(url, data)) as fp:
240 headers = fp.info()
241
~\anaconda3\lib\urllib\request.py in urlopen(url, data, timeout, cafile, capath, cadefault, context)
212 else:
213 opener = _opener
--> 214 return opener.open(url, data, timeout)
215
216 def install_opener(opener):
~\anaconda3\lib\urllib\request.py in open(self, fullurl, data, timeout)
515
516 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 517 response = self._open(req, data)
518
519 # post-process response
~\anaconda3\lib\urllib\request.py in _open(self, req, data)
532
533 protocol = req.type
--> 534 result = self._call_chain(self.handle_open, protocol, protocol +
535 '_open', req)
536 if result:
~\anaconda3\lib\urllib\request.py in _call_chain(self, chain, kind, meth_name, *args)
492 for handler in handlers:
493 func = getattr(handler, meth_name)
--> 494 result = func(*args)
495 if result is not None:
496 return result
~\anaconda3\lib\urllib\request.py in https_open(self, req)
1387
1388 def https_open(self, req):
-> 1389 return self.do_open(http.client.HTTPSConnection, req,
1390 context=self._context, check_hostname=self._check_hostname)
1391
~\anaconda3\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1347 encode_chunked=req.has_header('Transfer-encoding'))
1348 except OSError as err: # timeout error
-> 1349 raise URLError(err)
1350 r = h.getresponse()
1351 except:
URLError: <urlopen error [WinError 10060] A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond>
|
CLOSED
| 2023-02-16T14:01:58
| 2023-02-16T14:44:36
| 2023-02-16T14:44:36
|
https://github.com/huggingface/datasets/issues/5538
|
reemaranibarik
| 1
|
[] |
5,537
|
Increase speed of data files resolution
|
Certain datasets like `bigcode/the-stack-dedup` have so many files that loading them takes forever right from the data files resolution step.
`datasets` uses file patterns to check the structure of the repository but it takes too much time to iterate over and over again on all the data files.
This comes from `resolve_patterns_in_dataset_repository` which calls `_resolve_single_pattern_in_dataset_repository`, which iterates on all the files at
```python
glob_iter = [PurePath(filepath) for filepath in fs.glob(PurePath(pattern).as_posix()) if fs.isfile(filepath)]
```
but calling `glob` on such a dataset is too expensive. Indeed it calls `ls()` in `hffilesystem.py` too many times.
Maybe `glob` can be more optimized in `hffilesystem.py`, or the data files resolution can directly be implemented in the filesystem by checking its `dir_cache` ?
|
CLOSED
| 2023-02-16T12:11:45
| 2023-12-15T13:12:31
| 2023-12-15T13:12:31
|
https://github.com/huggingface/datasets/issues/5537
|
lhoestq
| 5
|
[
"enhancement",
"good second issue"
] |
5,536
|
Failure to hash function when using .map()
|
### Describe the bug
_Parameter 'function'=<function process at 0x7f1ec4388af0> of the transform datasets.arrow_dataset.Dataset.\_map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed._
This issue with `.map()` happens for me consistently, as also described in closed issue #4506
Dataset indices can be individually serialized using dill and pickle without any errors. I'm using tiktoken to encode in the function passed to map(). Similarly, indices can be individually encoded without error.
### Steps to reproduce the bug
```py
from datasets import load_dataset
import tiktoken
dataset = load_dataset("stas/openwebtext-10k")
enc = tiktoken.get_encoding("gpt2")
tokenized = dataset.map(
process,
remove_columns=['text'],
desc="tokenizing the OWT splits",
)
def process(example):
ids = enc.encode(example['text'])
ids.append(enc.eot_token)
out = {'ids': ids, 'len': len(ids)}
return out
```
### Expected behavior
Should encode simple text objects.
### Environment info
Python versions tried: both 3.8 and 3.10.10
`PYTHONUTF8=1` as env variable
Datasets tried:
- stas/openwebtext-10k
- rotten_tomatoes
- local text file
OS: Ubuntu Linux 20.04
Package versions:
- torch 1.13.1
- dill 0.3.4 (if using 0.3.6 - same issue)
- datasets 2.9.0
- tiktoken 0.2.0
|
CLOSED
| 2023-02-16T03:12:07
| 2023-09-08T21:06:01
| 2023-02-16T14:56:41
|
https://github.com/huggingface/datasets/issues/5536
|
venzen
| 14
|
[] |
5,534
|
map() breaks at certain dataset size when using Array3D
|
### Describe the bug
`map()` magically breaks when using a `Array3D` feature and mapping it. I created a very simple dummy dataset (see below). When filtering it down to 95 elements I can apply map, but it breaks when filtering it down to just 96 entries with the following exception:
```
Traceback (most recent call last):
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 3255, in _map_single
writer.finalize() # close_stream=bool(buf_writer is None)) # We only close if we are writing in a file
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_writer.py", line 581, in finalize
self.write_examples_on_file()
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_writer.py", line 440, in write_examples_on_file
batch_examples[col] = array_concat(arrays)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1931, in array_concat
return _concat_arrays(arrays)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1901, in _concat_arrays
return array_type.wrap_array(_concat_arrays([array.storage for array in arrays]))
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1922, in _concat_arrays
_concat_arrays([array.values for array in arrays]),
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1922, in _concat_arrays
_concat_arrays([array.values for array in arrays]),
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1920, in _concat_arrays
return pa.ListArray.from_arrays(
File "pyarrow/array.pxi", line 1997, in pyarrow.lib.ListArray.from_arrays
File "pyarrow/array.pxi", line 1527, in pyarrow.lib.Array.validate
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Negative offsets in list array
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2815, in map
return self._map_single(
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 546, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 513, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/fingerprint.py", line 480, in wrapper
out = func(self, *args, **kwargs)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 3259, in _map_single
writer.finalize()
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_writer.py", line 581, in finalize
self.write_examples_on_file()
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/arrow_writer.py", line 440, in write_examples_on_file
batch_examples[col] = array_concat(arrays)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1931, in array_concat
return _concat_arrays(arrays)
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1901, in _concat_arrays
return array_type.wrap_array(_concat_arrays([array.storage for array in arrays]))
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1922, in _concat_arrays
_concat_arrays([array.values for array in arrays]),
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1922, in _concat_arrays
_concat_arrays([array.values for array in arrays]),
File "/home/arbi01/miniconda3/envs/tmp9/lib/python3.9/site-packages/datasets/table.py", line 1920, in _concat_arrays
return pa.ListArray.from_arrays(
File "pyarrow/array.pxi", line 1997, in pyarrow.lib.ListArray.from_arrays
File "pyarrow/array.pxi", line 1527, in pyarrow.lib.Array.validate
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Negative offsets in list array
```
### Steps to reproduce the bug
1. put following dataset loading script into: debug/debug.py
```python
import datasets
import numpy as np
class DEBUG(datasets.GeneratorBasedBuilder):
"""DEBUG dataset."""
def _info(self):
return datasets.DatasetInfo(
features=datasets.Features(
{
"id": datasets.Value("uint8"),
"img_data": datasets.Array3D(shape=(3, 224, 224), dtype="uint8"),
},
),
supervised_keys=None,
)
def _split_generators(self, dl_manager):
return [datasets.SplitGenerator(name=datasets.Split.TRAIN)]
def _generate_examples(self):
for i in range(149):
image_np = np.zeros(shape=(3, 224, 224), dtype=np.int8).tolist()
yield f"id_{i}", {"id": i, "img_data": image_np}
```
2. try the following code:
```python
import datasets
def add_dummy_col(ex):
ex["dummy"] = "test"
return ex
ds = datasets.load_dataset(path="debug", split="train")
# works
ds_filtered_works = ds.filter(lambda example: example["id"] < 95)
print(f"filtered result size: {len(ds_filtered_works)}")
# output:
# filtered result size: 95
ds_mapped_works = ds_filtered_works.map(add_dummy_col)
# fails
ds_filtered_error = ds.filter(lambda example: example["id"] < 96)
print(f"filtered result size: {len(ds_filtered_error)}")
# output:
# filtered result size: 96
ds_mapped_error = ds_filtered_error.map(add_dummy_col)
```
### Expected behavior
The example code does not fail.
### Environment info
Python 3.9.16 (main, Jan 11 2023, 16:05:54); [GCC 11.2.0] :: Anaconda, Inc. on linux
datasets 2.9.0
|
OPEN
| 2023-02-15T16:34:25
| 2023-03-03T16:31:33
| null |
https://github.com/huggingface/datasets/issues/5534
|
ArneBinder
| 2
|
[] |
5,532
|
train_test_split in arrow_dataset does not ensure to keep single classes in test set
|
### Describe the bug
When I have a dataset with very few (e.g. 1) examples per class and I call the train_test_split function on it, sometimes the single class will be in the test set. thus will never be considered for training.
### Steps to reproduce the bug
```
import numpy as np
from datasets import Dataset
data = [
{'label': 0, 'text': "example1"},
{'label': 1, 'text': "example2"},
{'label': 1, 'text': "example3"},
{'label': 1, 'text': "example4"},
{'label': 0, 'text': "example5"},
{'label': 1, 'text': "example6"},
{'label': 2, 'text': "example7"},
{'label': 2, 'text': "example8"}
]
for _ in range(10):
data_set = Dataset.from_list(data)
data_set = data_set.train_test_split(test_size=0.5)
data_set["train"]
unique_labels_train = np.unique(data_set["train"][:]["label"])
unique_labels_test = np.unique(data_set["test"][:]["label"])
assert len(unique_labels_train) >= len(unique_labels_test)
```
### Expected behavior
I expect to have every available class at least once in my training set.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 11.0.0
- Pandas version: 1.3.5
|
CLOSED
| 2023-02-14T16:52:29
| 2023-02-15T16:09:19
| 2023-02-15T16:09:19
|
https://github.com/huggingface/datasets/issues/5532
|
Ulipenitz
| 1
|
[] |
5,531
|
Invalid Arrow data from JSONL
|
This code fails:
```python
from datasets import Dataset
ds = Dataset.from_json(path_to_file)
ds.data.validate()
```
raises
```python
ArrowInvalid: Column 2: In chunk 1: Invalid: Struct child array #3 invalid: Invalid: Length spanned by list offsets (4064) larger than values array (length 4063)
```
This causes many issues for @TevenLeScao:
- `map` fails because it fails to rewrite invalid arrow arrays
```python
~/Desktop/hf/datasets/src/datasets/arrow_writer.py in write_examples_on_file(self)
438 if all(isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) for row in self.current_examples):
439 arrays = [row[0][col] for row in self.current_examples]
--> 440 batch_examples[col] = array_concat(arrays)
441 else:
442 batch_examples[col] = [
~/Desktop/hf/datasets/src/datasets/table.py in array_concat(arrays)
1885
1886 if not _is_extension_type(array_type):
-> 1887 return pa.concat_arrays(arrays)
1888
1889 def _offsets_concat(offsets):
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib.concat_arrays()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.virtualenvs/hf-datasets/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowIndexError: array slice would exceed array length
```
- `to_dict()` **segfaults** ⚠️
```python
/Users/runner/work/crossbow/crossbow/arrow/cpp/src/arrow/array/data.cc:99: Check failed: (off) <= (length) Slice offset greater
than array length
```
To reproduce: unzip the archive and run the above code using `sanity_oscar_en.jsonl`
[sanity_oscar_en.jsonl.zip](https://github.com/huggingface/datasets/files/10734124/sanity_oscar_en.jsonl.zip)
PS: reading using pandas and converting to Arrow works though (note that the dataset lives in RAM in this case):
```python
ds = Dataset.from_pandas(pd.read_json(path_to_file, lines=True))
ds.data.validate()
```
|
OPEN
| 2023-02-14T15:39:49
| 2023-02-14T15:46:09
| null |
https://github.com/huggingface/datasets/issues/5531
|
lhoestq
| 0
|
[
"bug"
] |
5,525
|
TypeError: Couldn't cast array of type string to null
|
### Describe the bug
Processing a dataset I alredy uploaded to the Hub (https://huggingface.co/datasets/tj-solergibert/Europarl-ST) I found that for some splits and some languages (test split, source_lang = "nl") after applying a map function I get the mentioned error.
I alredy tried reseting the shorter strings (reset_cortas function). It only happends with NL, PL, RO and PT. It does not make sense since when processing the other languages I also use the corpus of those that fail and it does not cause any errors.
I suspect that the error may be in this direction:
We use cast_array_to_feature to support casting to custom types like Audio and Image # Also, when trying type "string", we don't want to convert integers or floats to "string". # We only do it if trying_type is False - since this is what the user asks for.
### Steps to reproduce the bug
Here I link a colab notebook to reproduce the error:
https://colab.research.google.com/drive/1JCrS7FlGfu_kFqChMrwKZ_bpabnIMqbP?authuser=1#scrollTo=FBAvlhMxIzpA
### Expected behavior
Data processing does not fail. A correct example can be seen here: https://huggingface.co/datasets/tj-solergibert/Europarl-ST-processed-mt-en
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
|
CLOSED
| 2023-02-10T21:12:36
| 2023-02-14T17:41:08
| 2023-02-14T09:35:49
|
https://github.com/huggingface/datasets/issues/5525
|
TJ-Solergibert
| 6
|
[] |
5,523
|
Checking that split name is correct happens only after the data is downloaded
|
### Describe the bug
Verification of split names (=indexing data by split) happens after downloading the data. So when the split name is incorrect, users learn about that only after the data is fully downloaded, for large datasets it might take a lot of time.
### Steps to reproduce the bug
Load any dataset with random split name, for example:
```python
from datasets import load_dataset
load_dataset("mozilla-foundation/common_voice_11_0", "en", split="blabla")
```
and the download will start smoothly, despite there is no split named "blabla".
### Expected behavior
Raise error when split name is incorrect.
### Environment info
`datasets==2.9.1.dev0`
|
OPEN
| 2023-02-10T19:13:03
| 2023-02-10T19:14:50
| null |
https://github.com/huggingface/datasets/issues/5523
|
polinaeterna
| 0
|
[
"bug"
] |
5,520
|
ClassLabel.cast_storage raises TypeError when called on an empty IntegerArray
|
### Describe the bug
`ClassLabel.cast_storage` raises `TypeError` when called on an empty `IntegerArray`.
### Steps to reproduce the bug
Minimal steps:
```python
import pyarrow as pa
from datasets import ClassLabel
ClassLabel(names=['foo', 'bar']).cast_storage(pa.array([], pa.int64()))
```
In practice, this bug arises in situations like the one below:
```python
from datasets import ClassLabel, Dataset, Features, Sequence
dataset = Dataset.from_dict({'labels': [[], []]}, features=Features({'labels': Sequence(ClassLabel(names=['foo', 'bar']))}))
# this raises TypeError
dataset.map(batched=True, batch_size=1)
```
### Expected behavior
`ClassLabel.cast_storage` should return an empty Int64Array.
### Environment info
- `datasets` version: 2.9.1.dev0
- Platform: Linux-4.15.0-1032-aws-x86_64-with-glibc2.27
- Python version: 3.10.6
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-09T18:46:52
| 2023-02-12T11:17:18
| 2023-02-12T11:17:18
|
https://github.com/huggingface/datasets/issues/5520
|
marioga
| 0
|
[] |
5,517
|
`with_format("numpy")` silently downcasts float64 to float32 features
|
### Describe the bug
When I create a dataset with a `float64` feature, then apply numpy formatting the returned numpy arrays are silently downcasted to `float32`.
### Steps to reproduce the bug
```python
import datasets
dataset = datasets.Dataset.from_dict({'a': [1.0, 2.0, 3.0]}).with_format("numpy")
print("feature dtype:", dataset.features['a'].dtype)
print("array dtype:", dataset['a'].dtype)
```
output:
```
feature dtype: float64
array dtype: float32
```
### Expected behavior
```
feature dtype: float64
array dtype: float64
```
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 10.0.1
- Pandas version: 1.4.4
### Suggested Fix
Changing [the `_tensorize` function of the numpy formatter](https://github.com/huggingface/datasets/blob/b065547654efa0ec633cf373ac1512884c68b2e1/src/datasets/formatting/np_formatter.py#L32) to
```python
def _tensorize(self, value):
if isinstance(value, (str, bytes, type(None))):
return value
elif isinstance(value, (np.character, np.ndarray)) and np.issubdtype(value.dtype, np.character):
return value
elif isinstance(value, np.number):
return value
return np.asarray(value, **self.np_array_kwargs)
```
fixes this particular issue for me. Not sure if this would break other tests. This should also avoid unnecessary copying of the array.
|
OPEN
| 2023-02-09T14:18:00
| 2024-01-18T08:42:17
| null |
https://github.com/huggingface/datasets/issues/5517
|
ernestum
| 13
|
[] |
5,514
|
Improve inconsistency of `Dataset.map` interface for `load_from_cache_file`
|
### Feature request
1. Replace the `load_from_cache_file` default value to `True`.
2. Remove or alter checks from `is_caching_enabled` logic.
### Motivation
I stumbled over an inconsistency in the `Dataset.map` interface. The documentation (and source) states for the parameter `load_from_cache_file`:
```
load_from_cache_file (`bool`, defaults to `True` if caching is enabled):
If a cache file storing the current computation from `function`
can be identified, use it instead of recomputing.
```
1. `load_from_cache_file` default value is `None`, while being annotated as `bool`
2. It is inconsistent with other method signatures like `filter`, that have the default value `True`
3. The logic is inconsistent, as the `map` method checks if caching is enabled through `is_caching_enabled`. This logic is not used for other similar methods.
### Your contribution
I am not fully aware of the logic behind caching checks. If this is just a inconsistency that historically grew, I would suggest to remove the `is_caching_enabled` logic as the "default" logic. Maybe someone can give insights, if environment variables have a higher priority than local variables or vice versa.
If this is clarified, I could adjust the source according to the "Feature request" section of this issue.
|
CLOSED
| 2023-02-08T16:40:44
| 2023-02-14T14:26:44
| 2023-02-14T14:26:44
|
https://github.com/huggingface/datasets/issues/5514
|
HallerPatrick
| 4
|
[
"enhancement"
] |
5,513
|
Some functions use a param named `type` shouldn't that be avoided since it's a Python reserved name?
|
Hi @mariosasko, @lhoestq, or whoever reads this! :)
After going through `ArrowDataset.set_format` I found out that the `type` param is actually named `type` which is a Python reserved name as you may already know, shouldn't that be renamed to `format_type` before the 3.0.0 is released?
Just wanted to get your input, and if applicable, tackle this issue myself! Thanks 🤗
|
CLOSED
| 2023-02-08T15:13:46
| 2023-07-24T16:02:18
| 2023-07-24T14:27:59
|
https://github.com/huggingface/datasets/issues/5513
|
alvarobartt
| 4
|
[] |
5,511
|
Creating a dummy dataset from a bigger one
|
### Describe the bug
I often want to create a dummy dataset from a bigger dataset for fast iteration when training. However, I'm having a hard time doing this especially when trying to upload the dataset to the Hub.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("lambdalabs/pokemon-blip-captions")
dataset["train"] = dataset["train"].select(range(20))
dataset.push_to_hub("patrickvonplaten/dummy_image_data")
```
gives:
```
~/python_bin/datasets/arrow_dataset.py in _push_parquet_shards_to_hub(self, repo_id, split, private, token, branch, max_shard_size, embed_external_files)
4003 base_wait_time=2.0,
4004 max_retries=5,
-> 4005 max_wait_time=20.0,
4006 )
4007 return repo_id, split, uploaded_size, dataset_nbytes
~/python_bin/datasets/utils/file_utils.py in _retry(func, func_args, func_kwargs, exceptions, status_codes, max_retries, base_wait_time, max_wait_time)
328 while True:
329 try:
--> 330 return func(*func_args, **func_kwargs)
331 except exceptions as err:
332 if retry >= max_retries or (status_codes and err.response.status_code not in status_codes):
~/hf/lib/python3.7/site-packages/huggingface_hub/utils/_validators.py in _inner_fn(*args, **kwargs)
122 )
123
--> 124 return fn(*args, **kwargs)
125
126 return _inner_fn # type: ignore
TypeError: upload_file() got an unexpected keyword argument 'identical_ok'
In [2]:
```
### Expected behavior
I would have expected this to work. It's for me the most intuitive way of creating a dummy dataset.
### Environment info
```
- `datasets` version: 2.1.1.dev0
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.3
- PyArrow version: 11.0.0
- Pandas version: 1.3.5
```
|
CLOSED
| 2023-02-08T10:18:41
| 2023-12-28T18:21:01
| 2023-02-08T10:35:48
|
https://github.com/huggingface/datasets/issues/5511
|
patrickvonplaten
| 8
|
[] |
5,508
|
Saving a dataset after setting format to torch doesn't work, but only if filtering
|
### Describe the bug
Saving a dataset after setting format to torch doesn't work, but only if filtering
### Steps to reproduce the bug
```
a = Dataset.from_dict({"b": [1, 2]})
a.set_format('torch')
a.save_to_disk("test_save") # saves successfully
a.filter(None).save_to_disk("test_save_filter") # does not
>> [...] TypeError: Provided `function` which is applied to all elements of table returns a `dict` of types [<class 'torch.Tensor'>]. When using `batched=True`, make sure provided `function` returns a `dict` of types like `(<class 'list'>, <class 'numpy.ndarray'>)`.
# note: skipping the format change to torch lets this work.
### Expected behavior
Saving to work
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-6.1.9-arch1-1-x86_64-with-glibc2.36
- Python version: 3.10.9
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
|
CLOSED
| 2023-02-06T21:08:58
| 2023-02-09T14:55:26
| 2023-02-09T14:55:26
|
https://github.com/huggingface/datasets/issues/5508
|
joebhakim
| 2
|
[] |
5,507
|
Optimise behaviour in respect to indices mapping
|
_Originally [posted](https://huggingface.slack.com/archives/C02V51Q3800/p1675443873878489?thread_ts=1675418893.373479&cid=C02V51Q3800) on Slack_
Considering all this, perhaps for Datasets 3.0, we can do the following:
* [ ] have `continuous=True` by default in `.shard` (requested in the survey and makes more sense for us since it doesn't create an indices mapping)
* [x] allow calling `save_to_disk` on "unflattened" datasets
* [ ] remove "hidden" expensive calls in `save_to_disk`, `unique`, `concatenate_datasets`, etc. For instance, instead of silently calling `flatten_indices` where it's needed, it's probably better to be explicit (considering how expensive these ops can be) and raise an error instead
|
OPEN
| 2023-02-06T14:25:55
| 2023-02-28T18:19:18
| null |
https://github.com/huggingface/datasets/issues/5507
|
mariosasko
| 0
|
[
"enhancement"
] |
5,506
|
IterableDataset and Dataset return different batch sizes when using Trainer with multiple GPUs
|
### Describe the bug
I am training a Roberta model using 2 GPUs and the `Trainer` API with a batch size of 256.
Initially I used a standard `Dataset`, but had issues with slow data loading. After reading [this issue](https://github.com/huggingface/datasets/issues/2252), I swapped to loading my dataset as contiguous shards and passing those to an `IterableDataset`. I observed an unexpected drop in GPU memory utilization, and found the batch size returned from the model had been cut in half.
When using `Trainer` with 2 GPUs and a batch size of 256, `Dataset` returns a batch of size 512 (256 per GPU), while `IterableDataset` returns a batch size of 256 (256 total). My guess is `IterableDataset` isn't accounting for multiple cards.
### Steps to reproduce the bug
```python
import datasets
from datasets import IterableDataset
from transformers import RobertaConfig
from transformers import RobertaTokenizerFast
from transformers import RobertaForMaskedLM
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
use_iterable_dataset = True
def gen_from_shards(shards):
for shard in shards:
for example in shard:
yield example
dataset = datasets.load_from_disk('my_dataset.hf')
if use_iterable_dataset:
n_shards = 100
shards = [dataset.shard(num_shards=n_shards, index=i) for i in range(n_shards)]
dataset = IterableDataset.from_generator(gen_from_shards, gen_kwargs={"shards": shards})
tokenizer = RobertaTokenizerFast.from_pretrained("./my_tokenizer", max_len=160, use_fast=True)
config = RobertaConfig(
vocab_size=8248,
max_position_embeddings=256,
num_attention_heads=8,
num_hidden_layers=6,
type_vocab_size=1)
model = RobertaForMaskedLM(config=config)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
training_args = TrainingArguments(
per_device_train_batch_size=256
# other args removed for brevity
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
trainer.train()
```
### Expected behavior
Expected `Dataset` and `IterableDataset` to have the same batch size behavior. If the current behavior is intentional, the batch size printout at the start of training should be updated. Currently, both dataset classes result in `Trainer` printing the same total batch size, even though the batch size sent to the GPUs are different.
### Environment info
datasets 2.7.1
transformers 4.25.1
|
CLOSED
| 2023-02-06T03:26:03
| 2023-02-08T18:30:08
| 2023-02-08T18:30:07
|
https://github.com/huggingface/datasets/issues/5506
|
kheyer
| 4
|
[] |
5,505
|
PyTorch BatchSampler still loads from Dataset one-by-one
|
### Describe the bug
In [the docs here](https://huggingface.co/docs/datasets/use_with_pytorch#use-a-batchsampler), it mentions the issue of the Dataset being read one-by-one, then states that using a BatchSampler resolves the issue.
I'm not sure if this is a mistake in the docs or the code, but it seems that the only way for a Dataset to be passed a list of indexes by PyTorch (instead of one index at a time) is to define a `__getitems__` method (note the plural) on the Dataset object, and since the HF Dataset doesn't have this, PyTorch executes [this line of code](https://github.com/pytorch/pytorch/blob/master/torch/utils/data/_utils/fetch.py#L58), reverting to fetching one-by-one.
### Steps to reproduce the bug
You can put a breakpoint in `Dataset.__getitem__()` or just print the args from there and see that it's called multiple times for a single `next(iter(dataloader))`, even when using the code from the docs:
```py
from torch.utils.data.sampler import BatchSampler, RandomSampler
batch_sampler = BatchSampler(RandomSampler(ds), batch_size=32, drop_last=False)
dataloader = DataLoader(ds, batch_sampler=batch_sampler)
```
### Expected behavior
The expected behaviour would be for it to fetch batches from the dataset, rather than one-by-one.
To demonstrate that there is room for improvement: once I have a HF dataset `ds`, if I just add this line:
```py
ds.__getitems__ = ds.__getitem__
```
...then the time taken to loop over the dataset improves considerably (for wikitext-103, from one minute to 13 seconds with batch size 32). Probably not a big deal in the grand scheme of things, but seems like an easy win.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-06T01:14:55
| 2023-02-19T18:27:30
| 2023-02-19T18:27:30
|
https://github.com/huggingface/datasets/issues/5505
|
davidgilbertson
| 2
|
[] |
5,500
|
WMT19 custom download checksum error
|
### Describe the bug
I use the following scripts to download data from WMT19:
```python
import datasets
from datasets import inspect_dataset, load_dataset_builder
from wmt19.wmt_utils import _TRAIN_SUBSETS,_DEV_SUBSETS
## this is a must due to: https://discuss.huggingface.co/t/load-dataset-hangs-with-local-files/28034/3
if __name__ == '__main__':
dev_subsets,train_subsets = [],[]
for subset in _TRAIN_SUBSETS:
if subset.target=='en' and 'de' in subset.sources:
train_subsets.append(subset.name)
for subset in _DEV_SUBSETS:
if subset.target=='en' and 'de' in subset.sources:
dev_subsets.append(subset.name)
inspect_dataset("wmt19", "./wmt19")
builder = load_dataset_builder(
"./wmt19/wmt_utils.py",
language_pair=("de", "en"),
subsets={
datasets.Split.TRAIN: train_subsets,
datasets.Split.VALIDATION: dev_subsets,
},
)
builder.download_and_prepare()
ds = builder.as_dataset()
ds.to_json("../data/wmt19/ende/data.json")
```
And I got the following error:
```
Traceback (most recent call last): | 0/2 [00:00<?, ?obj/s]
File "draft.py", line 26, in <module>
builder.download_and_prepare() | 0/1 [00:00<?, ?obj/s]
File "/Users/hannibal046/anaconda3/lib/python3.8/site-packages/datasets/builder.py", line 605, in download_and_prepare
self._download_and_prepare(%| | 0/1 [00:00<?, ?obj/s]
File "/Users/hannibal046/anaconda3/lib/python3.8/site-packages/datasets/builder.py", line 1104, in _download_and_prepare
super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos) | 0/1 [00:00<?, ?obj/s]
File "/Users/hannibal046/anaconda3/lib/python3.8/site-packages/datasets/builder.py", line 676, in _download_and_prepare
verify_checksums(s #13: 0%| | 0/1 [00:00<?, ?obj/s]
File "/Users/hannibal046/anaconda3/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 35, in verify_checksums
raise UnexpectedDownloadedFile(str(set(recorded_checksums) - set(expected_checksums))) | 0/1 [00:00<?, ?obj/s]
datasets.utils.info_utils.UnexpectedDownloadedFile: {'https://s3.amazonaws.com/web-language-models/paracrawl/release1/paracrawl-release1.en-de.zipporah0-dedup-clean.tgz', 'https://huggingface.co/datasets/wmt/wmt13/resolve/main-zip/training-parallel-europarl-v7.zip', 'https://huggingface.co/datasets/wmt/wmt18/resolve/main-zip/translation-task/rapid2016.zip', 'https://huggingface.co/datasets/wmt/wmt18/resolve/main-zip/translation-task/training-parallel-nc-v13.zip', 'https://huggingface.co/datasets/wmt/wmt17/resolve/main-zip/translation-task/training-parallel-nc-v12.zip', 'https://huggingface.co/datasets/wmt/wmt14/resolve/main-zip/training-parallel-nc-v9.zip', 'https://huggingface.co/datasets/wmt/wmt15/resolve/main-zip/training-parallel-nc-v10.zip', 'https://huggingface.co/datasets/wmt/wmt16/resolve/main-zip/translation-task/training-parallel-nc-v11.zip'}
```
### Steps to reproduce the bug
see above
### Expected behavior
download data successfully
### Environment info
datasets==2.1.0
python==3.8
|
CLOSED
| 2023-02-03T05:45:37
| 2023-02-03T05:52:56
| 2023-02-03T05:52:56
|
https://github.com/huggingface/datasets/issues/5500
|
Hannibal046
| 1
|
[] |
5,499
|
`load_dataset` has ~4 seconds of overhead for cached data
|
### Feature request
When loading a dataset that has been cached locally, the `load_dataset` function takes a lot longer than it should take to fetch the dataset from disk (or memory).
This is particularly noticeable for smaller datasets. For example, wikitext-2, comparing `load_data` (once cached) and `load_from_disk`, the `load_dataset` method takes 40 times longer.
⏱ 4.84s ⮜ load_dataset
⏱ 119ms ⮜ load_from_disk
### Motivation
I assume this is doing something like checking for a newer version.
If so, that's an age old problem: do you make the user wait _every single time they load from cache_ or do you do something like load from cache always, _then_ check for a newer version and alert if they have stale data. The decision usually revolves around what percentage of the time the data will have been updated, and how dangerous old data is.
For most datasets it's extremely unlikely that there will be a newer version on any given run, so 99% of the time this is just wasted time.
Maybe you don't want to make that decision for all users, but at least having the _option_ to not wait for checks would be an improvement.
### Your contribution
.
|
OPEN
| 2023-02-02T23:34:50
| 2023-02-07T19:35:11
| null |
https://github.com/huggingface/datasets/issues/5499
|
davidgilbertson
| 2
|
[
"enhancement"
] |
5,498
|
TypeError: 'bool' object is not iterable when filtering a datasets.arrow_dataset.Dataset
|
### Describe the bug
Hi,
Thanks for the amazing work on the library!
**Describe the bug**
I think I might have noticed a small bug in the filter method.
Having loaded a dataset using `load_dataset`, when I try to filter out empty entries with `batched=True`, I get a TypeError.
### Steps to reproduce the bug
```
train_dataset = train_dataset.filter(
function=lambda example: example["image"] is not None,
batched=True,
batch_size=10)
```
Error message:
```
File .../lib/python3.9/site-packages/datasets/fingerprint.py:480, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)
476 validate_fingerprint(kwargs[fingerprint_name])
478 # Call actual function
--> 480 out = func(self, *args, **kwargs)
...
-> 5666 indices_array = [i for i, to_keep in zip(indices, mask) if to_keep]
5667 if indices_mapping is not None:
5668 indices_array = pa.array(indices_array, type=pa.uint64())
TypeError: 'bool' object is not iterable
```
**Removing batched=True allows to bypass the issue.**
### Expected behavior
According to the doc, "[batch_size corresponds to the] number of examples per batch provided to function if batched = True", so we shouldn't need to remove the batchd=True arg?
source: https://huggingface.co/docs/datasets/v2.9.0/en/package_reference/main_classes#datasets.Dataset.filter
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.4.0-122-generic-x86_64-with-glibc2.31
- Python version: 3.9.10
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-02T14:46:49
| 2023-10-08T06:12:47
| 2023-02-04T17:19:36
|
https://github.com/huggingface/datasets/issues/5498
|
vmuel
| 3
|
[] |
5,496
|
Add a `reduce` method
|
### Feature request
Right now the `Dataset` class implements `map()` and `filter()`, but leaves out the third functional idiom popular among Python users: `reduce`.
### Motivation
A `reduce` method is often useful when calculating dataset statistics, for example, the occurrence of a particular n-gram or the average line length of a code dataset.
### Your contribution
I haven't contributed to `datasets` before, but I don't expect this will be too difficult, since the implementation will closely follow that of `map` and `filter`. I could have a crack over the weekend.
|
CLOSED
| 2023-02-02T04:30:22
| 2024-11-12T05:58:14
| 2023-07-21T14:24:32
|
https://github.com/huggingface/datasets/issues/5496
|
zhangir-azerbayev
| 4
|
[
"enhancement"
] |
5,495
|
to_tf_dataset fails with datetime UTC columns even if not included in columns argument
|
### Describe the bug
There appears to be some eager behavior in `to_tf_dataset` that runs against every column in a dataset even if they aren't included in the columns argument. This is problematic with datetime UTC columns due to them not working with zero copy. If I don't have UTC information in my datetime column, then everything works as expected.
### Steps to reproduce the bug
```python
import numpy as np
import pandas as pd
from datasets import Dataset
df = pd.DataFrame(np.random.rand(2, 1), columns=["x"])
# df["dt"] = pd.to_datetime(["2023-01-01", "2023-01-01"]) # works fine
df["dt"] = pd.to_datetime(["2023-01-01 00:00:00.00000+00:00", "2023-01-01 00:00:00.00000+00:00"])
df.to_parquet("test.pq")
ds = Dataset.from_parquet("test.pq")
tf_ds = ds.to_tf_dataset(columns=["x"], batch_size=2, shuffle=True)
```
```
ArrowInvalid Traceback (most recent call last)
Cell In[1], line 12
8 df.to_parquet("test.pq")
11 ds = Dataset.from_parquet("test.pq")
---> 12 tf_ds = ds.to_tf_dataset(columns=["r"], batch_size=2, shuffle=True)
File ~/venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:411, in TensorflowDatasetMixin.to_tf_dataset(self, batch_size, columns, shuffle, collate_fn, drop_remainder, collate_fn_args, label_cols, prefetch, num_workers)
407 dataset = self
409 # TODO(Matt, QL): deprecate the retention of label_ids and label
--> 411 output_signature, columns_to_np_types = dataset._get_output_signature(
412 dataset,
413 collate_fn=collate_fn,
414 collate_fn_args=collate_fn_args,
415 cols_to_retain=cols_to_retain,
416 batch_size=batch_size if drop_remainder else None,
417 )
419 if "labels" in output_signature:
420 if ("label_ids" in columns or "label" in columns) and "labels" not in columns:
File ~/venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:254, in TensorflowDatasetMixin._get_output_signature(dataset, collate_fn, collate_fn_args, cols_to_retain, batch_size, num_test_batches)
252 for _ in range(num_test_batches):
253 indices = sample(range(len(dataset)), test_batch_size)
--> 254 test_batch = dataset[indices]
255 if cols_to_retain is not None:
256 test_batch = {key: value for key, value in test_batch.items() if key in cols_to_retain}
File ~/venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:2590, in Dataset.__getitem__(self, key)
2588 def __getitem__(self, key): # noqa: F811
2589 """Can be used to index columns (by string names) or rows (by integer index or iterable of indices or bools)."""
-> 2590 return self._getitem(
2591 key,
2592 )
File ~/venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:2575, in Dataset._getitem(self, key, **kwargs)
2573 formatter = get_formatter(format_type, features=self.features, **format_kwargs)
2574 pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)
-> 2575 formatted_output = format_table(
2576 pa_subtable, key, formatter=formatter, format_columns=format_columns, output_all_columns=output_all_columns
2577 )
2578 return formatted_output
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:634, in format_table(table, key, formatter, format_columns, output_all_columns)
632 python_formatter = PythonFormatter(features=None)
633 if format_columns is None:
--> 634 return formatter(pa_table, query_type=query_type)
635 elif query_type == "column":
636 if key in format_columns:
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:410, in Formatter.__call__(self, pa_table, query_type)
408 return self.format_column(pa_table)
409 elif query_type == "batch":
--> 410 return self.format_batch(pa_table)
File ~/venv/lib/python3.8/site-packages/datasets/formatting/np_formatter.py:78, in NumpyFormatter.format_batch(self, pa_table)
77 def format_batch(self, pa_table: pa.Table) -> Mapping:
---> 78 batch = self.numpy_arrow_extractor().extract_batch(pa_table)
79 batch = self.python_features_decoder.decode_batch(batch)
80 batch = self.recursive_tensorize(batch)
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:164, in NumpyArrowExtractor.extract_batch(self, pa_table)
163 def extract_batch(self, pa_table: pa.Table) -> dict:
--> 164 return {col: self._arrow_array_to_numpy(pa_table[col]) for col in pa_table.column_names}
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:164, in <dictcomp>(.0)
163 def extract_batch(self, pa_table: pa.Table) -> dict:
--> 164 return {col: self._arrow_array_to_numpy(pa_table[col]) for col in pa_table.column_names}
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:185, in NumpyArrowExtractor._arrow_array_to_numpy(self, pa_array)
181 else:
182 zero_copy_only = _is_zero_copy_only(pa_array.type) and all(
183 not _is_array_with_nulls(chunk) for chunk in pa_array.chunks
184 )
--> 185 array: List = [
186 row for chunk in pa_array.chunks for row in chunk.to_numpy(zero_copy_only=zero_copy_only)
187 ]
188 else:
189 if isinstance(pa_array.type, _ArrayXDExtensionType):
190 # don't call to_pylist() to preserve dtype of the fixed-size array
File ~/venv/lib/python3.8/site-packages/datasets/formatting/formatting.py:186, in <listcomp>(.0)
181 else:
182 zero_copy_only = _is_zero_copy_only(pa_array.type) and all(
183 not _is_array_with_nulls(chunk) for chunk in pa_array.chunks
184 )
185 array: List = [
--> 186 row for chunk in pa_array.chunks for row in chunk.to_numpy(zero_copy_only=zero_copy_only)
187 ]
188 else:
189 if isinstance(pa_array.type, _ArrayXDExtensionType):
190 # don't call to_pylist() to preserve dtype of the fixed-size array
File ~/venv/lib/python3.8/site-packages/pyarrow/array.pxi:1475, in pyarrow.lib.Array.to_numpy()
File ~/venv/lib/python3.8/site-packages/pyarrow/error.pxi:100, in pyarrow.lib.check_status()
ArrowInvalid: Needed to copy 1 chunks with 0 nulls, but zero_copy_only was True
```
### Expected behavior
I think there are two potential issues/fixes
1. Proper handling of datetime UTC columns (perhaps there is something incorrect with zero copy handling here)
2. Not eagerly running against every column in a dataset when the columns argument of `to_tf_dataset` specifies a subset of columns (although I'm not sure if this is unavoidable)
### Environment info
- `datasets` version: 2.9.0
- Platform: macOS-13.2-x86_64-i386-64bit
- Python version: 3.8.12
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
CLOSED
| 2023-02-01T20:47:33
| 2023-02-08T14:33:19
| 2023-02-08T14:33:19
|
https://github.com/huggingface/datasets/issues/5495
|
dwyatte
| 2
|
[
"bug",
"good first issue"
] |
5,494
|
Update audio installation doc page
|
Our [installation documentation page](https://huggingface.co/docs/datasets/installation#audio) says that one can use Datasets for mp3 only with `torchaudio<0.12`. `torchaudio>0.12` is actually supported too but requires a specific version of ffmpeg which is not easily installed on all linux versions but there is a custom ubuntu repo for it, we have insctructions in the code: https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L327
So we should update the doc page. But first investigate [this issue](5488).
|
CLOSED
| 2023-02-01T19:07:50
| 2023-03-02T16:08:17
| 2023-03-02T16:08:17
|
https://github.com/huggingface/datasets/issues/5494
|
polinaeterna
| 4
|
[
"documentation"
] |
5,492
|
Push_to_hub in a pull request
|
Right now `ds.push_to_hub()` can push a dataset on `main` or on a new branch with `branch=`, but there is no way to open a pull request. Even passing `branch=refs/pr/x` doesn't seem to work: it tries to create a branch with that name
cc @nateraw
It should be possible to tweak the use of `huggingface_hub` in `push_to_hub` to make it open a PR or push to an existing PR
|
CLOSED
| 2023-02-01T18:32:14
| 2023-10-16T13:30:48
| 2023-10-16T13:30:48
|
https://github.com/huggingface/datasets/issues/5492
|
lhoestq
| 2
|
[
"enhancement",
"good first issue"
] |
5,488
|
Error loading MP3 files from CommonVoice
|
### Describe the bug
When loading a CommonVoice dataset with `datasets==2.9.0` and `torchaudio>=0.12.0`, I get an error reading the audio arrays:
```python
---------------------------------------------------------------------------
LibsndfileError Traceback (most recent call last)
~/.local/lib/python3.8/site-packages/datasets/features/audio.py in _decode_mp3(self, path_or_file)
310 try: # try torchaudio anyway because sometimes it works (depending on the os and os packages installed)
--> 311 array, sampling_rate = self._decode_mp3_torchaudio(path_or_file)
312 except RuntimeError:
~/.local/lib/python3.8/site-packages/datasets/features/audio.py in _decode_mp3_torchaudio(self, path_or_file)
351
--> 352 array, sampling_rate = torchaudio.load(path_or_file, format="mp3")
353 if self.sampling_rate and self.sampling_rate != sampling_rate:
~/.local/lib/python3.8/site-packages/torchaudio/backend/soundfile_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
204 """
--> 205 with soundfile.SoundFile(filepath, "r") as file_:
206 if file_.format != "WAV" or normalize:
~/.local/lib/python3.8/site-packages/soundfile.py in __init__(self, file, mode, samplerate, channels, subtype, endian, format, closefd)
654 format, subtype, endian)
--> 655 self._file = self._open(file, mode_int, closefd)
656 if set(mode).issuperset('r+') and self.seekable():
~/.local/lib/python3.8/site-packages/soundfile.py in _open(self, file, mode_int, closefd)
1212 err = _snd.sf_error(file_ptr)
-> 1213 raise LibsndfileError(err, prefix="Error opening {0!r}: ".format(self.name))
1214 if mode_int == _snd.SFM_WRITE:
LibsndfileError: Error opening <_io.BytesIO object at 0x7fa539462090>: File contains data in an unknown format.
```
I assume this is because there's some issue with the mp3 decoding process. I've verified that I have `ffmpeg>=4` (on a Linux distro), which appears to be the fallback backend for `torchaudio,` (at least according to #4889).
### Steps to reproduce the bug
```python
dataset = load_dataset("mozilla-foundation/common_voice_11_0", "be", split="train")
dataset[0]
```
### Expected behavior
Similar behavior to `torchaudio<0.12.0`, which doesn't result in a `LibsndfileError`
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 10.0.1
- Pandas version: 1.5.1
|
CLOSED
| 2023-01-31T21:25:33
| 2023-03-02T16:25:14
| 2023-03-02T16:25:13
|
https://github.com/huggingface/datasets/issues/5488
|
kradonneoh
| 4
|
[] |
5,487
|
Incorrect filepath for dill module
|
### Describe the bug
I installed the `datasets` package and when I try to `import` it, I get the following error:
```
Traceback (most recent call last):
File "/var/folders/jt/zw5g74ln6tqfdzsl8tx378j00000gn/T/ipykernel_3805/3458380017.py", line 1, in <module>
import datasets
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/__init__.py", line 43, in <module>
from .arrow_dataset import Dataset
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 66, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/arrow_writer.py", line 27, in <module>
from .features import Features, Image, Value
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/features/__init__.py", line 17, in <module>
from .audio import Audio
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/features/audio.py", line 12, in <module>
from ..download.streaming_download_manager import xopen
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/download/__init__.py", line 9, in <module>
from .download_manager import DownloadManager, DownloadMode
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/download/download_manager.py", line 36, in <module>
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 602, in <module>
class Pickler(dill.Pickler):
File "/Users/avivbrokman/opt/anaconda3/lib/python3.9/site-packages/datasets/utils/py_utils.py", line 605, in Pickler
dispatch = dill._dill.MetaCatchingDict(dill.Pickler.dispatch.copy())
AttributeError: module 'dill' has no attribute '_dill'
```
Looking at the github source code for dill, it appears that `datasets` has a bug or is not compatible with the latest `dill`. Specifically, rather than `dill._dill.XXXX` it should be `dill.dill._dill.XXXX`. But given the popularity of `datasets` I feel confused about me being the first person to have this issue, so it makes me wonder if I'm misdiagnosing the issue.
### Steps to reproduce the bug
Install `dill` and `datasets` packages and then `import datasets`
### Expected behavior
I expect `datasets` to import.
### Environment info
- `datasets` version: 2.9.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.13
- PyArrow version: 11.0.0
- Pandas version: 1.4.4
|
CLOSED
| 2023-01-31T15:01:08
| 2023-02-24T16:18:36
| 2023-02-24T16:18:36
|
https://github.com/huggingface/datasets/issues/5487
|
avivbrokman
| 5
|
[] |
5,486
|
Adding `sep` to TextConfig
|
I have a local a `.txt` file that follows the `CONLL2003` format which I need to load using `load_script`. However, by using `sample_by='line'`, one can only split the dataset into lines without splitting each line into columns. Would it be reasonable to add a `sep` argument in combination with `sample_by='paragraph'` to parse a paragraph into an array for each column ? If so, I am happy to contribute!
## Environment
* `python 3.8.10`
* `datasets 2.9.0`
## Snippet of `train.txt`
```txt
Distribution NN O O
and NN O O
dynamics NN O O
of NN O O
electron NN O B-RP
complexes NN O I-RP
in NN O O
cyanobacterial NN O B-R
membranes NN O I-R
The NN O O
occurrence NN O O
of NN O O
prostaglandin NN O B-R
F2α NN O I-R
in NN O O
Pharbitis NN O B-R
seedlings NN O I-R
grown NN O O
under NN O O
short NN O B-P
days NN O I-P
or NN O I-P
days NN O I-P
```
## Current Behaviour
```python
# defining 4 features ['tokens', 'pos_tags', 'chunk_tags', 'ner_tags'] here would fail with `ValueError: Length of names (4) does not match length of arrays (1)`
dataset = datasets.load_dataset(path='text', features=features, data_files={'train': 'train.txt'}, sample_by='line')
dataset['train']['tokens'][0]
>>> 'Distribution\tNN\tO\tO'
```
## Expected Behaviour / Suggestion
```python
# suppose we defined 4 features ['tokens', 'pos_tags', 'chunk_tags', 'ner_tags']
dataset = datasets.load_dataset(path='text', features=features, data_files={'train': 'train.txt'}, sample_by='paragraph', sep='\t')
dataset['train']['tokens'][0]
>>> ['Distribution', 'and', 'dynamics', ... ]
dataset['train']['ner_tags'][0]
>>> ['O', 'O', 'O', ... ]
```
|
OPEN
| 2023-01-31T10:39:53
| 2023-01-31T14:50:18
| null |
https://github.com/huggingface/datasets/issues/5486
|
omar-araboghli
| 2
|
[] |
5,483
|
Unable to upload dataset
|
### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.push_to_hub("ttt111")
/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_hf_folder.py:92: UserWarning: A token has been found in `/a/home/cc/students/cs/kirstain/.huggingface/token`. This is the old path where tokens were stored. The new location is `/home/olab/kirstain/.cache/huggingface/token` which is configurable using `HF_HOME` environment variable. Your token has been copied to this new location. You can now safely delete the old token file manually or use `huggingface-cli logout`.
warnings.warn(
Creating parquet from Arrow format: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 279.94ba/s]
Upload 1 LFS files: 0%| | 0/1 [00:02<?, ?it/s]
Pushing dataset shards to the dataset hub: 0%| | 0/1 [00:04<?, ?it/s]
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 264, in hf_raise_for_status
response.raise_for_status()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 334, in _inner_upload_lfs_object
return _upload_lfs_object(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 391, in _upload_lfs_object
lfs_upload(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 273, in lfs_upload
_upload_single_part(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 305, in _upload_single_part
hf_raise_for_status(upload_res)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 318, in hf_raise_for_status
raise HfHubHTTPError(str(e), response=response) from e
huggingface_hub.utils._errors.HfHubHTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4909, in push_to_hub
repo_id, split, uploaded_size, dataset_nbytes, repo_files, deleted_size = self._push_parquet_shards_to_hub(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4804, in _push_parquet_shards_to_hub
_retry(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 281, in _retry
return func(*func_args, **func_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2537, in upload_file
commit_info = self.create_commit(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2346, in create_commit
upload_lfs_files(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 346, in upload_lfs_files
thread_map(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 94, in thread_map
return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 76, in _executor_map
return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 621, in result_iterator
yield _result_or_cancel(fs.pop())
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 319, in _result_or_cancel
return fut.result(timeout)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 458, in result
return self.__get_result()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 338, in _inner_upload_lfs_object
raise RuntimeError(
RuntimeError: Error while uploading 'data/train-00000-of-00001-6df93048e66df326.parquet' to the Hub.
```
### Expected behavior
The dataset should be uploaded without any exceptions
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-4.15.0-65-generic-x86_64-with-glibc2.27
- Python version: 3.10.9
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
|
CLOSED
| 2023-01-28T15:18:26
| 2023-01-29T08:09:49
| 2023-01-29T08:09:49
|
https://github.com/huggingface/datasets/issues/5483
|
yuvalkirstain
| 1
|
[] |
5,482
|
Reload features from Parquet metadata
|
The idea would be to allow this :
```python
ds.to_parquet("my_dataset/ds.parquet")
reloaded = load_dataset("my_dataset")
assert ds.features == reloaded.features
```
And it should also work with Image and Audio types (right now they're reloaded as a dict type)
This can be implemented by storing and reading the feature types in the parquet metadata, as we do for arrow files.
|
CLOSED
| 2023-01-28T13:12:31
| 2023-02-12T15:57:02
| 2023-02-12T15:57:02
|
https://github.com/huggingface/datasets/issues/5482
|
lhoestq
| 3
|
[
"enhancement",
"good second issue"
] |
5,481
|
Load a cached dataset as iterable
|
The idea would be to allow something like
```python
ds = load_dataset("c4", "en", as_iterable=True)
```
To be used to train models. It would load an IterableDataset from the cached Arrow files.
Cc @stas00
Edit : from the discussions we may load from cache when streaming=True
|
OPEN
| 2023-01-27T21:43:51
| 2025-06-19T19:30:52
| null |
https://github.com/huggingface/datasets/issues/5481
|
lhoestq
| 22
|
[
"enhancement",
"good second issue"
] |
5,479
|
audiofolder works on local env, but creates empty dataset in a remote one, what dependencies could I be missing/outdated
|
### Describe the bug
I'm using a custom audio dataset (400+ audio files) in the correct format for audiofolder. Although loading the dataset with audiofolder works in one local setup, it doesn't in a remote one (it just creates an empty dataset). I have both ffmpeg and libndfile installed on both computers, what could be missing/need to be updated in the one that doesn't work? On the remote env, libsndfile is 1.0.28 and ffmpeg is 4.2.1.
from datasets import load_dataset
ds = load_dataset("audiofolder", data_dir="...")
Here is the output (should be generating 400+ rows):
Downloading and preparing dataset audiofolder/default to ...
Downloading data files: 0%| | 0/2 [00:00<?, ?it/s]
Downloading data files: 0it [00:00, ?it/s]
Extracting data files: 0it [00:00, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset audiofolder downloaded and prepared to ... Subsequent calls will reuse this data.
0%| | 0/1 [00:00<?, ?it/s]
DatasetDict({
train: Dataset({
features: ['audio', 'transcription'],
num_rows: 1
})
})
Here is my pip environment in the one that doesn't work (uses torch 1.11.a0 from shared env):
Package Version
------------------- -------------------
aiofiles 22.1.0
aiohttp 3.8.3
aiosignal 1.3.1
altair 4.2.1
anyio 3.6.2
appdirs 1.4.4
argcomplete 2.0.0
argon2-cffi 20.1.0
astunparse 1.6.3
async-timeout 4.0.2
attrs 21.2.0
audioread 3.0.0
backcall 0.2.0
bleach 4.0.0
certifi 2021.10.8
cffi 1.14.6
charset-normalizer 2.0.12
click 8.1.3
contourpy 1.0.7
cycler 0.11.0
datasets 2.9.0
debugpy 1.4.1
decorator 5.0.9
defusedxml 0.7.1
dill 0.3.6
distlib 0.3.4
entrypoints 0.3
evaluate 0.4.0
expecttest 0.1.3
fastapi 0.89.1
ffmpy 0.3.0
filelock 3.6.0
fonttools 4.38.0
frozenlist 1.3.3
fsspec 2023.1.0
future 0.18.2
gradio 3.16.2
h11 0.14.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.12.0
idna 3.3
ipykernel 6.2.0
ipython 7.26.0
ipython-genutils 0.2.0
ipywidgets 7.6.3
jedi 0.18.0
Jinja2 3.0.1
jiwer 2.5.1
joblib 1.2.0
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.1.12
jupyter-console 6.4.0
jupyter-core 4.7.1
jupyterlab-pygments 0.1.2
jupyterlab-widgets 1.0.0
kiwisolver 1.4.4
Levenshtein 0.20.2
librosa 0.9.2
linkify-it-py 1.0.3
llvmlite 0.39.1
markdown-it-py 2.1.0
MarkupSafe 2.0.1
matplotlib 3.6.3
matplotlib-inline 0.1.2
mdit-py-plugins 0.3.3
mdurl 0.1.2
mistune 0.8.4
multidict 6.0.4
multiprocess 0.70.14
nbclient 0.5.4
nbconvert 6.1.0
nbformat 5.1.3
nest-asyncio 1.5.1
notebook 6.4.3
numba 0.56.4
numpy 1.20.3
orjson 3.8.5
packaging 21.0
pandas 1.5.3
pandocfilters 1.4.3
parso 0.8.2
pexpect 4.8.0
pickleshare 0.7.5
Pillow 9.4.0
pip 22.3.1
pipx 1.1.0
platformdirs 2.5.2
pooch 1.6.0
prometheus-client 0.11.0
prompt-toolkit 3.0.19
psutil 5.9.0
ptyprocess 0.7.0
pyarrow 10.0.1
pycparser 2.20
pycryptodome 3.16.0
pydantic 1.10.4
pydub 0.25.1
Pygments 2.10.0
pyparsing 2.4.7
pyrsistent 0.18.0
python-dateutil 2.8.2
python-multipart 0.0.5
pytz 2022.7.1
PyYAML 6.0
pyzmq 22.2.1
qtconsole 5.1.1
QtPy 1.10.0
rapidfuzz 2.13.7
regex 2022.10.31
requests 2.27.1
resampy 0.4.2
responses 0.18.0
rfc3986 1.5.0
scikit-learn 1.2.1
scipy 1.6.3
Send2Trash 1.8.0
setuptools 65.5.1
shiboken6 6.3.1
shiboken6-generator 6.3.1
six 1.16.0
sniffio 1.3.0
soundfile 0.11.0
starlette 0.22.0
terminado 0.11.0
testpath 0.5.0
threadpoolctl 3.1.0
tokenizers 0.13.2
toolz 0.12.0
torch 1.11.0a0+gitunknown
tornado 6.1
tqdm 4.64.1
traitlets 5.0.5
transformers 4.27.0.dev0
types-dataclasses 0.6.4
typing_extensions 4.1.1
uc-micro-py 1.0.1
urllib3 1.26.9
userpath 1.8.0
uvicorn 0.20.0
virtualenv 20.14.1
wcwidth 0.2.5
webencodings 0.5.1
websockets 10.4
wheel 0.37.1
widgetsnbextension 3.5.1
xxhash 3.2.0
yarl 1.8.2
### Steps to reproduce the bug
Create a pip environment with the packages listed above (make sure ffmpeg and libsndfile is installed with same versions listed above).
Create a custom audio dataset and load it in with load_dataset("audiofolder", ...)
### Expected behavior
load_dataset should create a dataset with 400+ rows.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.0
- PyArrow version: 10.0.1
- Pandas version: 1.5.3
|
CLOSED
| 2023-01-27T20:01:22
| 2023-01-29T05:23:14
| 2023-01-29T05:23:14
|
https://github.com/huggingface/datasets/issues/5479
|
joseph-y-cho
| 0
|
[] |
5,477
|
Unpin sqlalchemy once issue is fixed
|
Once the source issue is fixed:
- pandas-dev/pandas#51015
we should revert the pin introduced in:
- #5476
|
CLOSED
| 2023-01-27T15:01:55
| 2024-01-26T14:50:45
| 2024-01-26T14:50:45
|
https://github.com/huggingface/datasets/issues/5477
|
albertvillanova
| 2
|
[] |
5,475
|
Dataset scan time is much slower than using native arrow
|
### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that explains this phenomenon?
### Steps to reproduce the bug
https://colab.research.google.com/drive/11EtHDaGAf1DKCpvYnAPJUW-LFfAcDzHY?usp=sharing
### Expected behavior
I expect scan times to be on par with using pyarrow directly.
### Environment info
standard colab environment
|
CLOSED
| 2023-01-27T01:32:25
| 2023-01-30T16:17:11
| 2023-01-30T16:17:11
|
https://github.com/huggingface/datasets/issues/5475
|
jonny-cyberhaven
| 3
|
[] |
5,474
|
Column project operation on `datasets.Dataset`
|
### Feature request
There is no operation to select a subset of columns of original dataset. Expected API follows.
```python
a = Dataset.from_dict({
'int': [0, 1, 2]
'char': ['a', 'b', 'c'],
'none': [None] * 3,
})
b = a.project('int', 'char') # usually, .select()
print(a.column_names) # stdout: ['int', 'char', 'none']
print(b.column_names) # stdout: ['int', 'char']
```
Method project can easily accept not only column names (as a `str)` but univariant function applied to corresponding column as an example. Or keyword arguments can be used in order to rename columns in advance (see `pandas`, `pyspark`, `pyarrow`, and SQL)..
### Motivation
Projection is a typical operation in every data processing library. And it is a basic block of a well-known data manipulation language like SQL. Without this operation `datasets.Dataset` interface is not complete.
### Your contribution
Not sure. Some of my PRs are still open and some do not have any discussions.
|
CLOSED
| 2023-01-26T21:47:53
| 2023-02-13T09:59:37
| 2023-02-13T09:59:37
|
https://github.com/huggingface/datasets/issues/5474
|
daskol
| 1
|
[
"duplicate",
"enhancement"
] |
5,468
|
Allow opposite of remove_columns on Dataset and DatasetDict
|
### Feature request
In this blog post https://huggingface.co/blog/audio-datasets, I noticed the following code:
```python
COLUMNS_TO_KEEP = ["text", "audio"]
all_columns = gigaspeech["train"].column_names
columns_to_remove = set(all_columns) - set(COLUMNS_TO_KEEP)
gigaspeech = gigaspeech.remove_columns(columns_to_remove)
```
This kind of thing happens a lot when you don't need to keep all columns from the dataset. It would be more convenient (and less error prone) if you could just write:
```python
gigaspeech = gigaspeech.keep_columns(["text", "audio"])
```
Internally, `keep_columns` could still call `remove_columns`, but it expresses more clearly what the user's intent is.
### Motivation
Less code to write for the user of the dataset.
### Your contribution
-
|
CLOSED
| 2023-01-26T12:28:09
| 2023-02-13T09:59:38
| 2023-02-13T09:59:38
|
https://github.com/huggingface/datasets/issues/5468
|
hollance
| 9
|
[
"enhancement",
"good first issue"
] |
5,465
|
audiofolder creates empty dataset even though the dataset passed in follows the correct structure
|
### Describe the bug
The structure of my dataset folder called "my_dataset" is : data metadata.csv
The data folder consists of all mp3 files and metadata.csv consist of file locations like 'data/...mp3 and transcriptions. There's 400+ mp3 files and corresponding transcriptions for my dataset.
When I run the following:
ds = load_dataset("audiofolder", data_dir="my_dataset")
I get:
Using custom data configuration default-...
Downloading and preparing dataset audiofolder/default to /...
Downloading data files: 0%| | 0/2 [00:00<?, ?it/s]
Downloading data files: 0it [00:00, ?it/s]
Extracting data files: 0it [00:00, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset audiofolder downloaded and prepared to /.... Subsequent calls will reuse this data.
0%| | 0/1 [00:00<?, ?it/s]
DatasetDict({
train: Dataset({
features: ['audio', 'transcription'],
num_rows: 1
})
})
### Steps to reproduce the bug
Create a dataset folder called 'my_dataset' with a subfolder called 'data' that has mp3 files. Also, create metadata.csv that has file locations like 'data/...mp3' and their corresponding transcription.
Run:
ds = load_dataset("audiofolder", data_dir="my_dataset")
### Expected behavior
It should generate a dataset with numerous rows.
### Environment info
Run on Jupyter notebook
|
CLOSED
| 2023-01-26T01:45:45
| 2023-01-26T08:48:45
| 2023-01-26T08:48:45
|
https://github.com/huggingface/datasets/issues/5465
|
joseph-y-cho
| 0
|
[] |
5,464
|
NonMatchingChecksumError for hendrycks_test
|
### Describe the bug
The checksum of the file has likely changed on the remote host.
### Steps to reproduce the bug
`dataset = nlp.load_dataset("hendrycks_test", "anatomy")`
### Expected behavior
no error thrown
### Environment info
- `datasets` version: 2.2.1
- Platform: macOS-13.1-arm64-arm-64bit
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1
|
CLOSED
| 2023-01-26T00:43:23
| 2023-01-27T05:44:31
| 2023-01-26T07:41:58
|
https://github.com/huggingface/datasets/issues/5464
|
sarahwie
| 2
|
[] |
5,461
|
Discrepancy in `nyu_depth_v2` dataset
|
### Describe the bug
I think there is a discrepancy between depth map of `nyu_depth_v2` dataset [here](https://huggingface.co/docs/datasets/main/en/depth_estimation) and actual depth map. Depth values somehow got **discretized/clipped** resulting in depth maps that are different from actual ones. Here is a side-by-side comparison,

I tried to find the origin of this issue but sadly as I mentioned in tensorflow/datasets/issues/4674, the download link from `fast-depth` doesn't work anymore hence couldn't verify if the error originated there or during porting data from there to HF.
Hi @sayakpaul, as you worked on huggingface/datasets/issues/5255, if you still have access to that data could you please share the data or perhaps checkout this issue?
### Steps to reproduce the bug
This [notebook](https://colab.research.google.com/drive/1K3ZU8XUPRDOYD38MQS9nreQXJYitlKSW?usp=sharing#scrollTo=UEW7QSh0jf0i) from @sayakpaul could be used to generate depth maps and actual ground truths could be checked from this [dataset](https://www.kaggle.com/datasets/awsaf49/nyuv2-bts-dataset) from BTS repo.
> Note: BTS dataset has only 36K data compared to the train-test 50K. They sampled the data as adjacent frames look quite the same
### Expected behavior
Expected depth maps should be smooth rather than discrete/clipped.
### Environment info
- `datasets` version: 2.8.1.dev0
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
|
OPEN
| 2023-01-24T19:15:46
| 2023-02-06T20:52:00
| null |
https://github.com/huggingface/datasets/issues/5461
|
awsaf49
| 37
|
[] |
5,458
|
slice split while streaming
|
### Describe the bug
When using the `load_dataset` function with streaming set to True, slicing splits is apparently not supported.
Did I miss this in the documentation?
### Steps to reproduce the bug
`load_dataset("lhoestq/demo1",revision=None, streaming=True, split="train[:3]")`
causes ValueError: Bad split: train[:3]. Available splits: ['train', 'test'] in builder.py, line 1213, in as_streaming_dataset
### Expected behavior
The first 3 entries of the dataset as a stream
### Environment info
- `datasets` version: 2.8.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.10.9
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
|
CLOSED
| 2023-01-24T14:08:17
| 2023-01-24T15:11:47
| 2023-01-24T15:11:47
|
https://github.com/huggingface/datasets/issues/5458
|
SvenDS9
| 2
|
[] |
5,457
|
prebuilt dataset relies on `downloads/extracted`
|
### Describe the bug
I pre-built the dataset:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
and it can be used just fine.
now I wipe out `downloads/extracted` and it no longer works.
```
rm -r ~/.cache/huggingface/datasets/downloads
```
That is I can still load it:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
No config specified, defaulting to: general-pmd-synthetic-testing/100.unique
Found cached dataset general-pmd-synthetic-testing (/home/stas/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing/100.unique/1.1.1/86bc445e3e48cb5ef79de109eb4e54ff85b318cd55c3835c4ee8f86eae33d9d2)
```
but if I try to use it:
```
E stderr: Traceback (most recent call last):
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/main.py", line 116, in <module>
E stderr: train_loader, val_loader = get_dataloaders(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 170, in get_dataloaders
E stderr: train_loader = get_dataloader_from_config(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 443, in get_dataloader_from_config
E stderr: dataloader = get_dataloader(
E stderr: File "/mnt/nvme0/code/huggingface/m4-master-6/m4/training/dataset.py", line 264, in get_dataloader
E stderr: is_pmd = "meta" in hf_dataset[0] and "source" in hf_dataset[0]
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2601, in __getitem__
E stderr: return self._getitem(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/arrow_dataset.py", line 2586, in _getitem
E stderr: formatted_output = format_table(
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 634, in format_table
E stderr: return formatter(pa_table, query_type=query_type)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 406, in __call__
E stderr: return self.format_row(pa_table)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 442, in format_row
E stderr: row = self.python_features_decoder.decode_row(row)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/formatting/formatting.py", line 225, in decode_row
E stderr: return self.features.decode_example(row) if self.features else row
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1846, in decode_example
E stderr: return {
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1847, in <dictcomp>
E stderr: column_name: decode_nested_example(feature, value, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1304, in decode_nested_example
E stderr: return decode_nested_example([schema.feature], obj)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1296, in decode_nested_example
E stderr: if decode_nested_example(sub_schema, first_elmt) != first_elmt:
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/features.py", line 1309, in decode_nested_example
E stderr: return schema.decode_example(obj, token_per_repo_id=token_per_repo_id)
E stderr: File "/mnt/nvme0/code/huggingface/datasets-master/src/datasets/features/image.py", line 144, in decode_example
E stderr: image = PIL.Image.open(path)
E stderr: File "/home/stas/anaconda3/envs/py38-pt113/lib/python3.8/site-packages/PIL/Image.py", line 3092, in open
E stderr: fp = builtins.open(filename, "rb")
E stderr: FileNotFoundError: [Errno 2] No such file or directory: '/mnt/nvme0/code/data/cache/huggingface/datasets/downloads/extracted/134227b9b94c4eccf19b205bf3021d4492d0227b9be6c2ddb6bf517d8d55a8cb/data/101/images_01.jpg'
```
Only if I wipe out the cached dir and rebuild then it starts working as `download/extracted` is back again with extracted files.
```
rm -r ~/.cache/huggingface/datasets/HuggingFaceM4___general-pmd-synthetic-testing
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
I think there are 2 issues here:
1. why does it still rely on extracted files after `arrow` files were printed - did I do something incorrectly when creating this dataset?
2. why doesn't the dataset know that it has been gutted and loads just fine? If it has a dependency on `download/extracted` then `load_dataset` should check if it's there and fail or force rebuilding. I am sure this could be a very expensive operation, so probably really solving #1 will not require this check. and this second item is probably an overkill. Other than perhaps if it had an optional `check_consistency` flag to do that.
### Environment info
datasets@main
|
OPEN
| 2023-01-24T02:09:32
| 2024-11-18T07:43:51
| null |
https://github.com/huggingface/datasets/issues/5457
|
stas00
| 3
|
[] |
5,454
|
Save and resume the state of a DataLoader
|
It would be nice when using `datasets` with a PyTorch DataLoader to be able to resume a training from a DataLoader state (e.g. to resume a training that crashed)
What I have in mind (but lmk if you have other ideas or comments):
For map-style datasets, this requires to have a PyTorch Sampler state that can be saved and reloaded per node and worker.
For iterable datasets, this requires to save the state of the dataset iterator, which includes:
- the current shard idx and row position in the current shard
- the epoch number
- the rng state
- the shuffle buffer
Right now you can already resume the data loading of an iterable dataset by using `IterableDataset.skip` but it takes a lot of time because it re-iterates on all the past data until it reaches the resuming point.
cc @stas00 @sgugger
|
OPEN
| 2023-01-23T10:58:54
| 2024-11-27T01:19:21
| null |
https://github.com/huggingface/datasets/issues/5454
|
lhoestq
| 21
|
[
"enhancement",
"generic discussion"
] |
5,451
|
ImageFolder BadZipFile: Bad offset for central directory
|
### Describe the bug
I'm getting the following exception:
```
lib/python3.10/zipfile.py:1353 in _RealGetContents │
│ │
│ 1350 │ │ # self.start_dir: Position of start of central directory │
│ 1351 │ │ self.start_dir = offset_cd + concat │
│ 1352 │ │ if self.start_dir < 0: │
│ ❱ 1353 │ │ │ raise BadZipFile("Bad offset for central directory") │
│ 1354 │ │ fp.seek(self.start_dir, 0) │
│ 1355 │ │ data = fp.read(size_cd) │
│ 1356 │ │ fp = io.BytesIO(data) │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
BadZipFile: Bad offset for central directory
Extracting data files: 35%|█████████████████▊ | 38572/110812 [00:10<00:20, 3576.26it/s]
```
### Steps to reproduce the bug
```
load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
),
```
### Expected behavior
loads the dataset
### Environment info
datasets==2.8.0
Python 3.10.8
Linux 129-146-3-202 5.15.0-52-generic #58~20.04.1-Ubuntu SMP Thu Oct 13 13:09:46 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
|
CLOSED
| 2023-01-22T23:50:12
| 2023-05-23T10:35:48
| 2023-02-10T16:31:36
|
https://github.com/huggingface/datasets/issues/5451
|
hmartiro
| 3
|
[] |
5,450
|
to_tf_dataset with a TF collator causes bizarrely persistent slowdown
|
### Describe the bug
This will make more sense if you take a look at [a Colab notebook that reproduces this issue.](https://colab.research.google.com/drive/1rxyeciQFWJTI0WrZ5aojp4Ls1ut18fNH?usp=sharing)
Briefly, there are several datasets that, when you iterate over them with `to_tf_dataset` **and** a data collator that returns `tf` tensors, become very slow. We haven't been able to figure this one out - it can be intermittent, and we have no idea what could possibly cause it. The weirdest thing is that **the slowdown affects other attempts to access the underlying dataset**. If you try to iterate over the `tf.data.Dataset`, then interrupt execution, and then try to iterate over the original dataset, the original dataset is now also very slow! This is true even if the dataset format is not set to `tf` - the iteration is slow even though it's not calling TF at all!
There is a simple workaround for this - we can simply get our data collators to return `np` tensors. When we do this, the bug is never triggered and everything is fine. In general, `np` is preferred for this kind of preprocessing work anyway, when the preprocessing is not going to be compiled into a pure `tf.data` pipeline! However, the issue is fascinating, and the TF team were wondering if anyone in datasets (cc @lhoestq @mariosasko) might have an idea of what could cause this.
### Steps to reproduce the bug
Run the attached Colab.
### Expected behavior
The slowdown should go away, or at least not persist after we stop iterating over the `tf.data.Dataset`
### Environment info
The issue occurs on multiple versions of Python and TF, both on local machines and on Colab.
All testing was done using the latest versions of `transformers` and `datasets` from `main`
|
CLOSED
| 2023-01-20T16:08:37
| 2023-02-13T14:13:34
| 2023-02-13T14:13:34
|
https://github.com/huggingface/datasets/issues/5450
|
Rocketknight1
| 7
|
[] |
5,448
|
Support fsspec 2023.1.0 in CI
|
Once we find out the root cause of:
- #5445
we should revert the temporary pin on fsspec introduced by:
- #5447
|
CLOSED
| 2023-01-20T10:26:31
| 2023-01-20T13:26:05
| 2023-01-20T13:26:05
|
https://github.com/huggingface/datasets/issues/5448
|
albertvillanova
| 0
|
[
"enhancement"
] |
5,445
|
CI tests are broken: AttributeError: 'mappingproxy' object has no attribute 'target'
|
CI tests are broken, raising `AttributeError: 'mappingproxy' object has no attribute 'target'`. See: https://github.com/huggingface/datasets/actions/runs/3966497597/jobs/6797384185
```
...
ERROR tests/test_streaming_download_manager.py::TestxPath::test_xpath_rglob[mock://top_level-date=2019-10-0[1-4]/*-expected_paths4] - AttributeError: 'mappingproxy' object has no attribute 'target'
===== 2076 passed, 19 skipped, 15 warnings, 47 errors in 115.54s (0:01:55) =====
```
|
CLOSED
| 2023-01-20T10:03:10
| 2023-01-20T10:28:44
| 2023-01-20T10:28:44
|
https://github.com/huggingface/datasets/issues/5445
|
albertvillanova
| 0
|
[
"bug"
] |
5,444
|
info messages logged as warnings
|
### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* INFO: Confirmation that things are working as expected.
* WARNING: An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected.
In theory, a user should be able to resolve things such that there are no warnings.
### Steps to reproduce the bug
Load any dataset that's already cached.
### Expected behavior
No output when log level is at the default WARNING level.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 9.0.0
- Pandas version: 1.5.2
|
CLOSED
| 2023-01-20T01:19:18
| 2023-07-12T17:19:31
| 2023-07-12T17:19:31
|
https://github.com/huggingface/datasets/issues/5444
|
davidgilbertson
| 7
|
[] |
5,442
|
OneDrive Integrations with HF Datasets
|
### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive** account and I want to move between drive and Hugging face repo or vis versa
### Motivation
make the dataset section more flexible with other possible storage
like the integration between Google Collab and Google drive the storage
### Your contribution
Can be done using Hugging face CLI
|
CLOSED
| 2023-01-19T23:12:08
| 2023-02-24T16:17:51
| 2023-02-24T16:17:51
|
https://github.com/huggingface/datasets/issues/5442
|
Mohammed20201991
| 2
|
[
"enhancement"
] |
5,439
|
[dataset request] Add Common Voice 12.0
|
### Feature request
Please add the common voice 12_0 datasets. Apart from English, a significant amount of audio-data has been added to the other minor-language datasets.
### Motivation
The dataset link:
https://commonvoice.mozilla.org/en/datasets
|
CLOSED
| 2023-01-18T13:07:05
| 2023-07-21T14:26:10
| 2023-07-21T14:26:09
|
https://github.com/huggingface/datasets/issues/5439
|
MohammedRakib
| 2
|
[
"enhancement"
] |
5,437
|
Can't load png dataset with 4 channel (RGBA)
|
I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand.
|
CLOSED
| 2023-01-17T18:22:27
| 2023-01-18T20:20:15
| 2023-01-18T20:20:15
|
https://github.com/huggingface/datasets/issues/5437
|
WiNE-iNEFF
| 3
|
[] |
5,435
|
Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage
|
### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples could come from other shards. In this case it only uses the shuffle buffer. Therefore it is advised to shuffle the dataset before splitting using take or skip. See more details in the [Shuffling the dataset: shuffle](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#iterable-dataset-shuffling) section.`
>> \# You can also create splits from a shuffled dataset
>> train_dataset = shuffled_dataset.skip(1000)
>> eval_dataset = shuffled_dataset.take(1000)
Where the shuffled dataset comes from:
`shuffled_dataset = dataset.shuffle(buffer_size=10_000, seed=42)`
At least in Tensorflow 2.9/2.10/2.11, [docs](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#shuffle) states the `reshuffle_each_iteration` argument is `True` by default. This means the dataset would be shuffled after each epoch, and as a result **the validation data would leak into training test**.
### Steps to reproduce the bug
N/A
### Expected behavior
The `reshuffle_each_iteration` argument should be set to `False`.
### Environment info
Tensorflow 2.9/2.10/2.11
|
CLOSED
| 2023-01-17T10:04:16
| 2023-01-19T09:56:03
| 2023-01-19T09:56:03
|
https://github.com/huggingface/datasets/issues/5435
|
DanielYang59
| 4
|
[] |
5,434
|
sample_dataset module not found
|
CLOSED
| 2023-01-17T09:57:54
| 2023-01-19T13:52:12
| 2023-01-19T07:55:11
|
https://github.com/huggingface/datasets/issues/5434
|
nickums
| 3
|
[] |
|
5,433
|
Support latest Docker image in CI benchmarks
|
Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432
|
CLOSED
| 2023-01-17T09:06:08
| 2023-01-18T06:29:08
| 2023-01-18T06:29:08
|
https://github.com/huggingface/datasets/issues/5433
|
albertvillanova
| 3
|
[
"enhancement"
] |
5,431
|
CI benchmarks are broken: Unknown arguments: runnerPath, path
|
Our CI benchmarks are broken, raising `Unknown arguments` error: https://github.com/huggingface/datasets/actions/runs/3932397079/jobs/6724905161
```
Unknown arguments: runnerPath, path
```
Stack trace:
```
100%|██████████| 500/500 [00:01<00:00, 338.98ba/s]
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
cml send-comment <markdown file>
Global Options:
--log Logging verbosity
[string] [choices: "error", "warn", "info", "debug"] [default: "info"]
--driver Git provider where the repository is hosted
[string] [choices: "github", "gitlab", "bitbucket"] [default: infer from the
environment]
--repo Repository URL or slug
[string] [default: infer from the environment]
--driver-token, --token CI driver personal/project access token (PAT)
[string] [default: infer from the environment]
--help Show help [boolean]
Options:
--target Comment type (`commit`, `pr`, `commit/f00bar`,
`pr/42`, `issue/1337`),default is automatic (`pr`
but fallback to `commit`). [string]
--watch Watch for changes and automatically update the
comment [boolean]
--publish Upload any local images found in the Markdown
report [boolean] [default: true]
--publish-url Self-hosted image server URL
[string] [default: "https://asset.cml.dev/"]
--publish-native, --native Uses driver's native capabilities to upload assets
instead of CML's storage; not available on GitHub
[boolean]
--watermark-title Hidden comment marker (used for targeting in
subsequent `cml comment update`); "{workflow}" &
"{run}" are auto-replaced [string] [default: ""]
Unknown arguments: runnerPath, path
Error: Process completed with exit code 1.
```
Issue reported to iterative/cml:
- iterative/cml#1319
|
CLOSED
| 2023-01-17T06:49:57
| 2023-01-18T06:33:24
| 2023-01-17T08:51:18
|
https://github.com/huggingface/datasets/issues/5431
|
albertvillanova
| 0
|
[
"maintenance"
] |
5,430
|
Support Apache Beam >= 2.44.0
|
Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429
|
CLOSED
| 2023-01-17T06:42:12
| 2024-02-06T19:24:21
| 2024-02-06T19:24:21
|
https://github.com/huggingface/datasets/issues/5430
|
albertvillanova
| 1
|
[
"enhancement"
] |
5,428
|
Load/Save FAISS index using fsspec
|
### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In my case, I'm saving faiss index in cloud storage and use `fsspec` to load them. It would be ideal if I could send the stream directly instead of copying the file locally (or mounting the bucket) and then load the index.
### Your contribution
I can submit the PR
|
CLOSED
| 2023-01-16T16:08:12
| 2023-03-27T15:18:22
| 2023-03-27T15:18:22
|
https://github.com/huggingface/datasets/issues/5428
|
Dref360
| 2
|
[
"enhancement"
] |
5,427
|
Unable to download dataset id_clickbait
|
### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>NoSuchBucket</Code><Message>The specified bucket does not exist</Message><BucketName>md-datasets-cache-zipfiles-prod</BucketName><RequestId>NVRM6VEEQD69SD00</RequestId><HostId>W/SPDxLGvlCGi0OD6d7mSDvfOAUqLAfvs9nTX50BkJrjMny+X9Jnqp/Li2lG9eTUuT4MUkAA2jjTfCrCiUmu7A==</HostId></Error>
```
### Steps to reproduce the bug
Code snippet:
```
from datasets import load_dataset
load_dataset('id_clickbait', 'annotated')
load_dataset('id_clickbait', 'raw')
```
Link to Kaggle notebook: https://www.kaggle.com/code/ilosvigil/bug-check-on-id-clickbait-dataset
### Expected behavior
Successfully download and load `id_newspaper` dataset.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
|
CLOSED
| 2023-01-16T16:05:36
| 2023-01-18T09:51:28
| 2023-01-18T09:25:19
|
https://github.com/huggingface/datasets/issues/5427
|
ilos-vigil
| 1
|
[] |
5,426
|
CI tests are broken: SchemaInferenceError
|
CI test (unit, ubuntu-latest, deps-minimum) is broken, raising a `SchemaInferenceError`: see https://github.com/huggingface/datasets/actions/runs/3930901593/jobs/6721492004
```
FAILED tests/test_beam.py::BeamBuilderTest::test_download_and_prepare_sharded - datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
```
Stack trace:
```
______________ BeamBuilderTest.test_download_and_prepare_sharded _______________
[gw1] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
self = <tests.test_beam.BeamBuilderTest testMethod=test_download_and_prepare_sharded>
@require_beam
def test_download_and_prepare_sharded(self):
import apache_beam as beam
original_write_parquet = beam.io.parquetio.WriteToParquet
expected_num_examples = len(get_test_dummy_examples())
with tempfile.TemporaryDirectory() as tmp_cache_dir:
builder = DummyBeamDataset(cache_dir=tmp_cache_dir, beam_runner="DirectRunner")
with patch("apache_beam.io.parquetio.WriteToParquet") as write_parquet_mock:
write_parquet_mock.side_effect = partial(original_write_parquet, num_shards=2)
> builder.download_and_prepare()
tests/test_beam.py:97:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:864: in download_and_prepare
**download_and_prepare_kwargs,
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:1976: in _download_and_prepare
num_examples, num_bytes = beam_writer.finalize(metrics.query(m_filter))
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:694: in finalize
shard_num_bytes, _ = parquet_to_arrow(source, destination)
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:740: in parquet_to_arrow
num_bytes, num_examples = writer.finalize()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <datasets.arrow_writer.ArrowWriter object at 0x7f6dcbb3e810>
close_stream = True
def finalize(self, close_stream=True):
self.write_rows_on_file()
# In case current_examples < writer_batch_size, but user uses finalize()
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
# If schema is known, infer features even if no examples were written
if self.pa_writer is None and self.schema:
self._build_writer(self.schema)
if self.pa_writer is not None:
self.pa_writer.close()
self.pa_writer = None
if close_stream:
self.stream.close()
else:
if close_stream:
self.stream.close()
> raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
E datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:593: SchemaInferenceError
```
|
CLOSED
| 2023-01-16T16:02:07
| 2023-06-02T06:40:32
| 2023-01-16T16:49:04
|
https://github.com/huggingface/datasets/issues/5426
|
albertvillanova
| 0
|
[
"bug"
] |
5,425
|
Sort on multiple keys with datasets.Dataset.sort()
|
### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to pandas and be able to specify multiple columns for sorting. We’re already using pandas under the hood to do the sorting in datasets.
The suggested workaround:
> convert your dataset to pandas and use `df.sort_values()`
### Motivation
Preserved ordering when sorting is very handy when one needs to sort on multiple columns, A and B, so that e.g. whenever A is equal for two or more rows, B is kept sorted.
Having a parameter to do this in 🤗datasets would be cleaner than going through pandas and back, and it wouldn't add much complexity to the library.
Alternatives:
- the possibility to specify multiple keys to sort by with decreasing priority (suggested solution),
- the ability to provide a key function for sorting, so that one can manually specify the sorting criteria.
### Your contribution
I'll be happy to contribute by submitting a PR. Will get documented on `CONTRIBUTING.MD`.
Would love to get thoughts on this, if anyone has anything to add.
|
CLOSED
| 2023-01-16T09:22:26
| 2023-02-24T16:15:11
| 2023-02-24T16:15:11
|
https://github.com/huggingface/datasets/issues/5425
|
rocco-fortuna
| 10
|
[
"enhancement",
"good first issue"
] |
5,424
|
When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset?
|
### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduce the behaviour:
1. Import
`from datasets import load_dataset, ReadInstruction`
2. Instruction to load the dataset
```
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="test", from_=0, to=5, unit='%', rounding='closest')
]
```
3. Load
`dataset = load_dataset('csv', data_dir="data/", data_files={"train":"train.tsv", "dev":"dev.tsv", "test":"test.tsv"}, delimiter="\t", split=instructions)`
### Expected behavior
**Current behaviour**
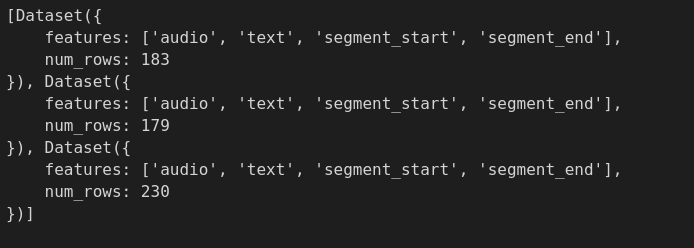
:
**Expected behaviour**
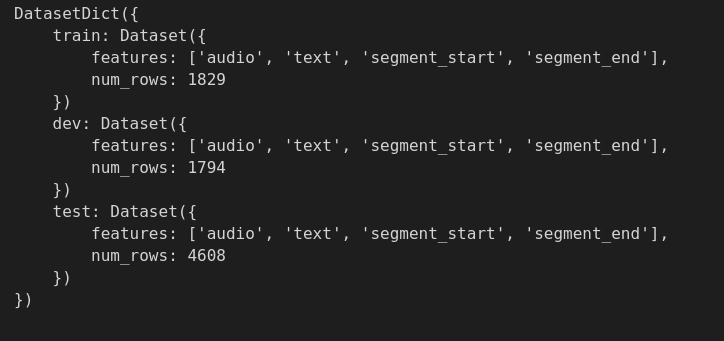
### Environment info
``datasets==2.8.0
``
`Python==3.8.5
`
`Platform - Ubuntu 20.04.4 LTS`
|
CLOSED
| 2023-01-16T06:54:28
| 2023-02-24T16:19:00
| 2023-02-24T16:19:00
|
https://github.com/huggingface/datasets/issues/5424
|
macabdul9
| 1
|
[] |
5,422
|
Datasets load error for saved github issues
|
### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
A work-around I found was to use streaming.
### Steps to reproduce the bug
Reproduce by executing the code provided:
https://huggingface.co/course/chapter5/5?fw=pt
From the heading:
'let’s create a function that can download all the issues from a GitHub repository'
### Expected behavior
No error
### Environment info
Datasets version 2.8.0. Note that version 2.6.1 gives the same error (related to null timestamp).
**[EDIT]**
This is the complete error trace confirming the issue is related to the timestamp (`Couldn't cast array of type timestamp[s] to null`)
```
Using custom data configuration default-950028611d2860c8
Downloading and preparing dataset json/default to [...]/.cache/huggingface/datasets/json/default-950028611d2860c8/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51...
Downloading data files: 100%|██████████| 1/1 [00:00<?, ?it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 500.63it/s]
Generating train split: 2619 examples [00:00, 7155.72 examples/s]Traceback (most recent call last):
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1831, in _prepare_split_single
writer.write_table(table)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\arrow_writer.py", line 567, in write_table
pa_table = table_cast(pa_table, self._schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2282, in table_cast
return cast_table_to_schema(table, schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2101, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1990, in array_cast
raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
TypeError: Couldn't cast array of type timestamp[s] to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 1, in <module>
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py", line 198, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "[...]\PycharmProjects\TransformersTesting\dataset_issues.py", line 20, in <module>
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\load.py", line 1757, in load_dataset
builder_instance.download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 860, in download_and_prepare
self._download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 953, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1706, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1849, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
Generating train split: 2619 examples [00:19, 7155.72 examples/s]
```
|
OPEN
| 2023-01-14T17:29:38
| 2023-09-14T11:39:57
| null |
https://github.com/huggingface/datasets/issues/5422
|
folterj
| 7
|
[] |
5,421
|
Support case-insensitive Hub dataset name in load_dataset
|
### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from datasets import load_dataset
load_dataset('GLUE', 'cola')
```
It breaks because the loading script `GLUE.py` does not exist (`glue.py` should be selected instead).
Minor additional comment: in other cases without a loading script, we can load the dataset, but the automatically generated config name depends on the casing:
- `load_dataset('severo/danish-wit')` generates the config name `severo--danish-wit-e6fda5b070deb133`, while
- `load_dataset('severo/danish-WIT')` generates the config name `severo--danish-WIT-e6fda5b070deb133`
### Motivation
To follow the same UX on the Hub and in the datasets library.
### Your contribution
...
|
CLOSED
| 2023-01-13T13:07:07
| 2023-01-13T20:12:32
| 2023-01-13T20:12:32
|
https://github.com/huggingface/datasets/issues/5421
|
severo
| 1
|
[
"enhancement"
] |
5,419
|
label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator
|
### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column accordingly to the expected name : `label` or `label_ids`
### Steps to reproduce the bug
```python
from datasets import TextClassification, AutoTokenized, DataCollatorWithPadding
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0'))
print(ds_prepared)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
ds_tokenized = ds_prepared.map(lambda x: tokenizer(x['text'], truncation=True), batched=True)
print(ds_tokenized)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_data = model.prepare_tf_dataset(ds_tokenized, shuffle=True, batch_size=16, collate_fn=data_collator)
print(tf_data)
```
### Expected behavior
Without renaming the the column, the target column is not in the final tf_data since it is not in the column name expected by the data_collator.
To correct this, we have to rename the column:
```python
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0')).rename_column('labels', 'label')
```
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
- `transformers` version: 4.26.0.dev0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.11.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
|
CLOSED
| 2023-01-13T09:40:07
| 2023-07-21T14:27:08
| 2023-07-21T14:27:08
|
https://github.com/huggingface/datasets/issues/5419
|
CreatixEA
| 2
|
[] |
5,418
|
Add ProgressBar for `to_parquet`
|
### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed
|
CLOSED
| 2023-01-12T05:06:20
| 2023-01-24T18:18:24
| 2023-01-24T18:18:24
|
https://github.com/huggingface/datasets/issues/5418
|
zanussbaum
| 4
|
[
"enhancement"
] |
5,415
|
RuntimeError: Sharding is ambiguous for this dataset
|
### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1415 fpath = path_join(self._output_dir, fname)
1416
-> 1417 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1418 if num_input_shards <= 1 and num_proc is not None:
1419 logger.warning(
.../huggingface/datasets/src/datasets/utils/sharding.py in _number_of_shards_in_gen_kwargs(gen_kwargs)
10 lists_lengths = {key: len(value) for key, value in gen_kwargs.items() if isinstance(value, list)}
11 if len(set(lists_lengths.values())) > 1:
---> 12 raise RuntimeError(
13 (
14 "Sharding is ambiguous for this dataset: "
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key samples_paths has length 6
- key ids has length 7
- key verification_ids has length 6
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
This behavior was introduced when implementing multiprocessing by PR:
- #5107
### Steps to reproduce the bug
```python
ds = load_dataset("ami", "microphone-single", split="train", revision="2d7620bb7c3f1aab9f329615c3bdb598069d907a")
```
### Expected behavior
No error raised.
### Environment info
Since datasets 2.7.0
|
CLOSED
| 2023-01-10T07:36:11
| 2023-01-18T14:09:04
| 2023-01-18T14:09:03
|
https://github.com/huggingface/datasets/issues/5415
|
albertvillanova
| 0
|
[] |
5,414
|
Sharding error with Multilingual LibriSpeech
|
### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/2.1.0/1904af50f57a5c370c9364cc337699cfe496d4e9edcae6648a96be23086362d0...
Downloading data files: 100%
3/3 [00:00<00:00, 107.23it/s]
Downloading data files: 100%
1/1 [00:00<00:00, 35.08it/s]
Downloading data files: 100%
6/6 [00:00<00:00, 303.36it/s]
Downloading data files: 100%
3/3 [00:00<00:00, 130.37it/s]
Downloading data files: 100%
1049/1049 [00:00<00:00, 4491.40it/s]
Downloading data files: 100%
37/37 [00:00<00:00, 1096.78it/s]
Downloading data files: 100%
40/40 [00:00<00:00, 1003.93it/s]
Extracting data files: 100%
3/3 [00:11<00:00, 2.62s/it]
Generating train split:
469942/0 [34:13<00:00, 273.21 examples/s]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-74fa6d092bdc> in <module>
----> 1 mls = load_dataset(MLS_DATASET,
2 LANGUAGE,
3 cache_dir="~/datadrive/cache/huggingface/datasets",
4 ignore_verifications=True)
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1755
1756 # Download and prepare data
-> 1757 builder_instance.download_and_prepare(
1758 download_config=download_config,
1759 download_mode=download_mode,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
858 if num_proc is not None:
859 prepare_split_kwargs["num_proc"] = num_proc
--> 860 self._download_and_prepare(
861 dl_manager=dl_manager,
862 verify_infos=verify_infos,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1609
1610 def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
...
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_archives has length 1049
- key local_extracted_archive has length 1049
- key limited_ids_paths has length 1
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
### Steps to reproduce the bug
Here is the code to reproduce it:
```python
from datasets import load_dataset
MLS_DATASET = "facebook/multilingual_librispeech"
LANGUAGE = "german"
mls = load_dataset(MLS_DATASET,
LANGUAGE,
cache_dir="~/datadrive/cache/huggingface/datasets",
ignore_verifications=True)
```
### Expected behavior
The expected behaviour is that the dataset is successfully loaded.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-1094-azure-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 10.0.1
- Pandas version: 1.2.4
|
CLOSED
| 2023-01-09T14:45:31
| 2023-01-18T14:09:04
| 2023-01-18T14:09:04
|
https://github.com/huggingface/datasets/issues/5414
|
Nithin-Holla
| 4
|
[] |
5,413
|
concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers
|
### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 5499, in _concatenate_map_style_datasets
table = concat_tables([dset._data for dset in dsets], axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1778, in concat_tables
return ConcatenationTable.from_tables(tables, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1483, in from_tables
blocks = _extend_blocks(blocks, table_blocks, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1477, in _extend_blocks
result[i].extend(row_blocks)
IndexError: list index out of range
```
### Steps to reproduce the bug
dataset = concatenate_datasets([dataset1, dataset2], axis = 1)
### Expected behavior
The datasets are correctly concatenated.
### Environment info
datasets==2.8.0
|
CLOSED
| 2023-01-08T17:01:52
| 2023-01-26T09:27:21
| 2023-01-26T09:27:21
|
https://github.com/huggingface/datasets/issues/5413
|
ZeguanXiao
| 1
|
[] |
5,412
|
load_dataset() cannot find dataset_info.json with multiple training runs in parallel
|
### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would solve my problem too.
I am using datasets version 2.8.0.
### Steps to reproduce the bug
1. Start training run of GPU 0 loading dataset from
```
load_dataset(
"json",
data_files=tr_dataset_path,
split=f"train",
download_mode="force_redownload",
)
```
2. While GPU 0 is training, start an identical run on GPU 1. GPU 1 will produce the following error:
```
Traceback (most recent call last):
File "/local-scratch1/data/mt/code/qq/train.py", line 198, in <module>
main()
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/local-scratch1/data/mt/code/qq/train.py", line 113, in main
load_dataset(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1734, in load_dataset
builder_instance = load_dataset_builder(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1518, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/builder.py", line 366, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/info.py", line 313, in from_directory
with fs.open(path_join(dataset_info_dir, config.DATASET_INFO_FILENAME), "r", encoding="utf-8") as f:
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1094, in open
self.open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1106, in open
f = self._open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 175, in _open
return LocalFileOpener(path, mode, fs=self, **kwargs)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 273, in __init__
self._open()
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 278, in _open
self.f = open(self.path, mode=self.mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/username/.cache/huggingface/datasets/json/default-43d06a4aedb25e6d/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51/dataset_info.json'
```
### Expected behavior
Expected behavior: 2nd GPU training run should run the same as 1st GPU training run.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 9.0.0
- Pandas version: 1.5.2
|
CLOSED
| 2023-01-08T00:44:32
| 2023-01-19T20:28:43
| 2023-01-19T20:28:43
|
https://github.com/huggingface/datasets/issues/5412
|
mtoles
| 4
|
[] |
5,408
|
dataset map function could not be hash properly
|
### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)`
> Parameter 'function'=<function prepare_dataset at 0x000001D1D9D79A60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
I read https://github.com/huggingface/datasets/issues/4521 and https://github.com/huggingface/datasets/issues/3178 but cannot solve the issue.
### Steps to reproduce the bug
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="train+validation")
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="test")
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
from transformers import WhisperFeatureExtractor, WhisperTokenizer, WhisperProcessor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"],
sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)
```
### Expected behavior
Should be no warning shown.
### Environment info
- `datasets` version: 2.7.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
- dill version: 0.3.4
- multiprocess version: 0.70.12.2
|
CLOSED
| 2023-01-05T01:59:59
| 2023-01-06T13:22:19
| 2023-01-06T13:22:18
|
https://github.com/huggingface/datasets/issues/5408
|
Tungway1990
| 2
|
[] |
5,407
|
Datasets.from_sql() generates deprecation warning
|
### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the bug
Any valid call to `Datasets.from_sql()` will produce the deprecation warning.
### Expected behavior
No warning.
The fix should be simply to remove the parameter `use_auth_token` from the call to `builder.download_and_prepare()` at line 43 of `io/sql.py` (it is set to `None` anyway, and is not needed).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-4.15.0-169-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
|
CLOSED
| 2023-01-05T00:43:17
| 2023-01-06T10:59:14
| 2023-01-06T10:59:14
|
https://github.com/huggingface/datasets/issues/5407
|
msummerfield
| 1
|
[] |
5,406
|
[2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
|
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadata of those datasets to a format that is not supported in 2.6.1 and 2.7.0
This change is required or those datasets won't be supported by the Hugging Face Hub.
Therefore if you encounter this error or if you're using `datasets` 2.6.1 or 2.7.0, we encourage you to update to a newer version.
For example, versions 2.6.2 and 2.7.1 patch this issue.
```python
pip install -U datasets
```
All the datasets affected are the ones with a ClassLabel feature type and YAML "dataset_info" metadata. More info [here](https://github.com/huggingface/datasets/issues/5275).
We apologize for the inconvenience.
|
OPEN
| 2023-01-04T15:10:04
| 2023-06-21T18:45:38
| null |
https://github.com/huggingface/datasets/issues/5406
|
lhoestq
| 11
|
[] |
5,405
|
size_in_bytes the same for all splits
|
### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
Found cached dataset glue (/Users/breakend/.cache/huggingface/datasets/glue/wnli/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1097.70it/s]
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
>>>
```
### Steps to reproduce the bug
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
```
### Expected behavior
The expected behavior is that it should return the separate sizes for all splits.
### Environment info
- `datasets` version: 2.7.1
- Platform: macOS-12.5-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
|
OPEN
| 2023-01-03T20:25:48
| 2023-01-04T09:22:59
| null |
https://github.com/huggingface/datasets/issues/5405
|
Breakend
| 1
|
[] |
5,404
|
Better integration of BIG-bench
|
### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906
|
OPEN
| 2023-01-03T15:37:57
| 2023-02-09T20:30:26
| null |
https://github.com/huggingface/datasets/issues/5404
|
albertvillanova
| 1
|
[
"enhancement"
] |
5,402
|
Missing state.json when creating a cloud dataset using a dataset_builder
|
### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
As a comparison, if you use the non lazy `load_dataset`, it works and the S3 folder has different structure + state.json files. Example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_dataset, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
dataset = load_dataset("imdb",)
dataset.save_to_disk(output_dir, fs=fs)
load_from_disk(output_dir, fs=fs) # WORKS
```
You still want the 1st option for the laziness and the parquet conversion. Thanks!
### Steps to reproduce the bug
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
BTW, you need the AioSession as s3fs is now based on aiobotocore, see https://github.com/fsspec/s3fs/issues/385.
### Expected behavior
Expected to be able to load the dataset from S3.
### Environment info
```
s3fs 2022.11.0
s3transfer 0.6.0
datasets 2.8.0
aiobotocore 2.4.2
boto3 1.24.59
botocore 1.27.59
```
python 3.7.15.
|
OPEN
| 2023-01-03T13:39:59
| 2023-01-04T17:23:57
| null |
https://github.com/huggingface/datasets/issues/5402
|
danielfleischer
| 3
|
[] |
5,399
|
Got disconnected from remote data host. Retrying in 5sec [2/20]
|
### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Image(decode=True),
'caption': Value(dtype='string'),
})
#make sure u r logged in to HF
ds = Dataset.from_pandas(df, features=features)
ds.features
ds.push_to_hub("x/x")
```
I got the below error and It always stops at the same progress
```
100%|██████████| 4/4 [23:53<00:00, 358.48s/ba]
100%|██████████| 4/4 [24:37<00:00, 369.47s/ba]%|▍ | 1/22 [00:06<02:09, 6.16s/it]
100%|██████████| 4/4 [25:00<00:00, 375.15s/ba]%|▉ | 2/22 [25:54<2:36:15, 468.80s/it]
100%|██████████| 4/4 [24:53<00:00, 373.29s/ba]%|█▎ | 3/22 [51:01<4:07:07, 780.39s/it]
100%|██████████| 4/4 [24:01<00:00, 360.34s/ba]%|█▊ | 4/22 [1:17:00<5:04:07, 1013.74s/it]
100%|██████████| 4/4 [23:59<00:00, 359.91s/ba]%|██▎ | 5/22 [1:41:07<5:24:06, 1143.90s/it]
100%|██████████| 4/4 [24:16<00:00, 364.06s/ba]%|██▋ | 6/22 [2:05:14<5:29:15, 1234.74s/it]
100%|██████████| 4/4 [25:24<00:00, 381.10s/ba]%|███▏ | 7/22 [2:29:38<5:25:52, 1303.52s/it]
100%|██████████| 4/4 [25:24<00:00, 381.24s/ba]%|███▋ | 8/22 [2:56:02<5:23:46, 1387.58s/it]
100%|██████████| 4/4 [25:08<00:00, 377.23s/ba]%|████ | 9/22 [3:22:24<5:13:17, 1445.97s/it]
100%|██████████| 4/4 [24:11<00:00, 362.87s/ba]%|████▌ | 10/22 [3:48:24<4:56:02, 1480.19s/it]
100%|██████████| 4/4 [24:44<00:00, 371.11s/ba]%|█████ | 11/22 [4:12:42<4:30:10, 1473.66s/it]
100%|██████████| 4/4 [24:35<00:00, 368.81s/ba]%|█████▍ | 12/22 [4:37:34<4:06:29, 1478.98s/it]
100%|██████████| 4/4 [24:02<00:00, 360.67s/ba]%|█████▉ | 13/22 [5:03:24<3:45:04, 1500.45s/it]
100%|██████████| 4/4 [24:07<00:00, 361.78s/ba]%|██████▎ | 14/22 [5:27:33<3:17:59, 1484.97s/it]
100%|██████████| 4/4 [23:39<00:00, 354.85s/ba]%|██████▊ | 15/22 [5:51:48<2:52:10, 1475.82s/it]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:16:58<2:28:37, 1486.31s/it]Got disconnected from remote data host. Retrying in 5sec [1/20]
Got disconnected from remote data host. Retrying in 5sec [2/20]
Got disconnected from remote data host. Retrying in 5sec [3/20]
Got disconnected from remote data host. Retrying in 5sec [4/20]
Got disconnected from remote data host. Retrying in 5sec [5/20]
Got disconnected from remote data host. Retrying in 5sec [6/20]
Got disconnected from remote data host. Retrying in 5sec [7/20]
Got disconnected from remote data host. Retrying in 5sec [8/20]
Got disconnected from remote data host. Retrying in 5sec [9/20]
...
Got disconnected from remote data host. Retrying in 5sec [19/20]
Got disconnected from remote data host. Retrying in 5sec [20/20]
75%|███████▌ | 3/4 [24:47<08:15, 495.86s/ba]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:41:46<2:30:39, 1506.65s/it]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
<ipython-input-1-dbf8530779e9> in <module>
16 ds.features
```
### Expected behavior
I was trying to upload an image dataset and expected it to be fully uploaded
### Environment info
- `datasets` version: 2.8.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.9
- PyArrow version: 10.0.1
- Pandas version: 1.3.5
|
CLOSED
| 2023-01-01T13:00:11
| 2023-01-02T07:21:52
| 2023-01-02T07:21:52
|
https://github.com/huggingface/datasets/issues/5399
|
alhuri
| 0
|
[] |
5,398
|
Unpin pydantic
|
Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395
|
CLOSED
| 2022-12-30T10:37:31
| 2022-12-30T10:43:41
| 2022-12-30T10:43:41
|
https://github.com/huggingface/datasets/issues/5398
|
albertvillanova
| 0
|
[] |
5,394
|
CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
|
### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 142, in _get_module_details
return _get_module_details(pkg_main_name, error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 109, in _get_module_details
__import__(pkg_name)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/__init__.py", line 6, in <module>
from .errors import setup_default_warnings
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/errors.py", line 2, in <module>
from .compat import Literal
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/compat.py", line 3, in <module>
from thinc.util import copy_array
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/__init__.py", line 5, in <module>
from .config import registry
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/config.py", line 2, in <module>
import confection
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/confection/__init__.py", line 10, in <module>
from pydantic import BaseModel, create_model, ValidationError, Extra
File "pydantic/__init__.py", line 2, in init pydantic.__init__
File "pydantic/dataclasses.py", line 46, in init pydantic.dataclasses
# | None | Attribute is set to None. |
File "pydantic/main.py", line 121, in init pydantic.main
TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
```
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565
### Steps to reproduce the bug
```shell
pip install .[tests,metrics-tests]
python -m spacy download en_core_web_sm
```
### Expected behavior
No error.
### Environment info
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565
|
CLOSED
| 2022-12-29T18:58:44
| 2022-12-30T10:40:51
| 2022-12-29T21:00:27
|
https://github.com/huggingface/datasets/issues/5394
|
albertvillanova
| 2
|
[] |
5,391
|
Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it]
|
Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 - WEB](https://discuss.huggingface.co/t/trainer-runtimeerror-the-size-of-tensor-a-462-must-match-the-size-of-tensor-b-448-at-non-singleton-dimension-1/26010/10 ) - another person experiencing the same issue. But could not resolve the issue with the google/fleurs data. __Not clear what can be modified in the PY code to resolve the input data size mismatch, as the training data is already very small__.
Tried posting on Discord, @sanchit-gandhi and @vaibhavs10. Was hoping that the event is over and some input/help is now available. [Hugging Face - whisper-small-amet](https://huggingface.co/drmeeseeks/whisper-small-amet).
The paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356) am_et is a low resource language (Table E), with the WER results ranging from 120-229, based on model size. (Whisper small WER=120.2).
# ---> Initial Training Output
/usr/local/lib/python3.8/dist-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
[INFO|trainer.py:1641] 2022-12-18 05:23:28,799 >> ***** Running training *****
[INFO|trainer.py:1642] 2022-12-18 05:23:28,799 >> Num examples = 446
[INFO|trainer.py:1643] 2022-12-18 05:23:28,799 >> Num Epochs = 72
[INFO|trainer.py:1644] 2022-12-18 05:23:28,799 >> Instantaneous batch size per device = 16
[INFO|trainer.py:1645] 2022-12-18 05:23:28,799 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:1646] 2022-12-18 05:23:28,799 >> Gradient Accumulation steps = 2
[INFO|trainer.py:1647] 2022-12-18 05:23:28,800 >> Total optimization steps = 1000
[INFO|trainer.py:1648] 2022-12-18 05:23:28,801 >> Number of trainable parameters = 241734912
# ---> Error
14% 9/65 [07:07<48:34, 52.04s/it][INFO|configuration_utils.py:523] 2022-12-18 05:03:07,941 >> Generate config GenerationConfig {
"begin_suppress_tokens": [
220,
50257
],
"bos_token_id": 50257,
"decoder_start_token_id": 50258,
"eos_token_id": 50257,
"max_length": 448,
"pad_token_id": 50257,
"transformers_version": "4.26.0.dev0",
"use_cache": false
}
Traceback (most recent call last):
File "run_speech_recognition_seq2seq_streaming.py", line 629, in <module>
main()
File "run_speech_recognition_seq2seq_streaming.py", line 578, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1534, in train
return inner_training_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1859, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2122, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 78, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2818, in evaluate
output = eval_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 3000, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 213, in prediction_step
outputs = model(**inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1197, in forward
outputs = self.model(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1066, in forward
decoder_outputs = self.decoder(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 873, in forward
hidden_states = inputs_embeds + positions
RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1
100% 1000/1000 [2:52:21<00:00, 10.34s/it]
|
CLOSED
| 2022-12-25T15:17:14
| 2023-07-21T14:29:47
| 2023-07-21T14:29:47
|
https://github.com/huggingface/datasets/issues/5391
|
catswithbats
| 2
|
[] |
5,390
|
Error when pushing to the CI hub
|
### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.93s/it]
Traceback (most recent call last):
File "reproduce_hubci.py", line 16, in <module>
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
File "/home/slesage/hf/datasets/src/datasets/arrow_dataset.py", line 5025, in push_to_hub
HfApi(endpoint=config.HF_ENDPOINT).upload_file(
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1346, in upload_file
raise err
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1337, in upload_file
r.raise_for_status()
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/requests/models.py", line 953, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_DATASETS_SERVER_USER__/bug-16718047265472/upload/main/README.md
```
### Steps to reproduce the bug
```python
# reproduce.py
from datasets import Dataset
import time
USER = "__DUMMY_DATASETS_SERVER_USER__"
USER_TOKEN = "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"
dataset = Dataset.from_dict({"a": [1, 2, 3]})
repo_id = f"{USER}/bug-{int(time.time() * 10e3)}"
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
```
```bash
$ HF_ENDPOINT="https://hub-ci.huggingface.co" python reproduce.py
```
### Expected behavior
No error and the dataset should be uploaded to the Hub with the README file (which generates the error).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.0-1026-aws-x86_64-with-glibc2.35
- Python version: 3.9.15
- PyArrow version: 7.0.0
- Pandas version: 1.5.2
|
CLOSED
| 2022-12-23T13:36:37
| 2022-12-23T20:29:02
| 2022-12-23T20:29:02
|
https://github.com/huggingface/datasets/issues/5390
|
severo
| 5
|
[] |
5,388
|
Getting Value Error while loading a dataset..
|
### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-12-5b4fdcb8e6d5>](https://localhost:8080/#) in <module>
6 )
7
----> 8 next(iter(law_dataset_streamed))
17 frames
[/usr/local/lib/python3.8/dist-packages/fsspec/core.py](https://localhost:8080/#) in get_compression(urlpath, compression)
485 compression = infer_compression(urlpath)
486 if compression is not None and compression not in compr:
--> 487 raise ValueError("Compression type %s not supported" % compression)
488 return compression
489
ValueError: Compression type zstd not supported
```
### Steps to reproduce the bug
```
!pip install zstandard
from datasets import load_dataset
lds = load_dataset(
"json",
data_files="https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
)
```
### Expected behavior
I expect an iterable object as the output 'lds' to be created.
### Environment info
Windows laptop with Google Colab notebook
|
CLOSED
| 2022-12-23T08:16:43
| 2022-12-29T08:36:33
| 2022-12-27T17:59:09
|
https://github.com/huggingface/datasets/issues/5388
|
valmetisrinivas
| 4
|
[] |
5,387
|
Missing documentation page : improve-performance
|
### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce the bug
Access the page and see it's missing.
### Expected behavior
Not missing page
### Environment info
Doesn't matter
|
CLOSED
| 2022-12-23T01:12:57
| 2023-01-24T16:33:40
| 2023-01-24T16:33:40
|
https://github.com/huggingface/datasets/issues/5387
|
astariul
| 1
|
[] |
5,386
|
`max_shard_size` in `datasets.push_to_hub()` breaks with large files
|
### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_size='100MB'` results in shard files that are `>2GB` in size. Setting `max_shard_size` to another value, such as `1GB` or `500MB` does not fix this problem.
**The real problem is this:** When the shard file size grows too big, the entire dataset breaks because of #4721 and ultimately https://issues.apache.org/jira/browse/ARROW-5030. Since `max_shard_size` does not let one accurately control the size of the shard files, it becomes very easy to build a large dataset without any warnings that it will be broken -- even when you think you are mitigating this problem by setting `max_shard_size`.
```
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/builder.py", line 1763, in _prepare_split_single
for _, table in generator:
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/packaged_modules/parquet/parquet.py", line 69, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
```
### Steps to reproduce the bug
1. Clone [example repo](https://github.com/salieri/hf-dataset-shard-size-bug)
2. Follow steps in [README.md](https://github.com/salieri/hf-dataset-shard-size-bug/blob/main/README.md)
3. After uploading the dataset, you will see that the shard file size varies between `30MB` and `200MB` -- way beyond the `max_shard_size='75MB'` limit (example: `train-00003-of-00131...` is `155MB` in [here](https://huggingface.co/datasets/slri/shard-size-test/tree/main/data))
(Note that this example repo does not generate shard files that are so large that they would trigger #4721)
### Expected behavior
The shard file size should remain below or equal to `max_shard_size`.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.157-139.675.amzn2.aarch64-aarch64-with-glibc2.17
- Python version: 3.7.15
- PyArrow version: 10.0.1
- Pandas version: 1.3.5
|
CLOSED
| 2022-12-22T21:50:58
| 2022-12-26T23:45:51
| 2022-12-26T23:45:51
|
https://github.com/huggingface/datasets/issues/5386
|
salieri
| 2
|
[] |
5,385
|
Is `fs=` deprecated in `load_from_disk()` as well?
|
### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the same thing shouldn't also apply to `datasets.load.load_from_disk()` as well ?
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/load.py#L1779
### Steps to reproduce the bug
n/a
### Expected behavior
n/a
### Environment info
n/a
|
CLOSED
| 2022-12-22T21:00:45
| 2023-01-23T10:50:05
| 2023-01-23T10:50:04
|
https://github.com/huggingface/datasets/issues/5385
|
dconathan
| 3
|
[] |
5,383
|
IterableDataset missing column_names, differs from Dataset interface
|
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.column_names` does not exist on IterableDataset. I cannot find any clear explanation on why this is not available, is it an oversight? We do have `iterable_ds.features` available.
### Steps to reproduce the bug
See above
### Expected behavior
Dataset and IterableDataset would be expected to have the same interface, with any differences noted in the documentation.
### Environment info
n/a
|
CLOSED
| 2022-12-22T05:27:02
| 2023-03-13T19:03:33
| 2023-03-13T19:03:33
|
https://github.com/huggingface/datasets/issues/5383
|
iceboundflame
| 6
|
[
"enhancement",
"good first issue"
] |
5,381
|
Wrong URL for the_pile dataset
|
### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message": "Unable to resolve any data file that matches '['**']' at /storage/store/work/lgrinszt/memorization/the_pile with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'BLP', 'BMP', 'DIB', 'BUFR', 'CUR', 'PCX', 'DCX', 'DDS', 'PS', 'EPS', 'FIT', 'FITS', 'FLI', 'FLC', 'FTC', 'FTU', 'GBR', 'GIF', 'GRIB', 'H5', 'HDF', 'PNG', 'APNG', 'JP2', 'J2K', 'JPC', 'JPF', 'JPX', 'J2C', 'ICNS', 'ICO', 'IM', 'IIM', 'TIF', 'TIFF', 'JFIF', 'JPE', 'JPG', 'JPEG', 'MPG', 'MPEG', 'MSP', 'PCD', 'PXR', 'PBM', 'PGM', 'PPM', 'PNM', 'PSD', 'BW', 'RGB', 'RGBA', 'SGI', 'RAS', 'TGA', 'ICB', 'VDA', 'VST', 'WEBP', 'WMF', 'EMF', 'XBM', 'XPM', 'aiff', 'au', 'avr', 'caf', 'flac', 'htk', 'svx', 'mat4', 'mat5', 'mpc2k', 'ogg', 'paf', 'pvf', 'raw', 'rf64', 'sd2', 'sds', 'ircam', 'voc', 'w64', 'wav', 'nist', 'wavex', 'wve', 'xi', 'mp3', 'opus', 'AIFF', 'AU', 'AVR', 'CAF', 'FLAC', 'HTK', 'SVX', 'MAT4', 'MAT5', 'MPC2K', 'OGG', 'PAF', 'PVF', 'RAW', 'RF64', 'SD2', 'SDS', 'IRCAM', 'VOC', 'W64', 'WAV', 'NIST', 'WAVEX', 'WVE', 'XI', 'MP3', 'OPUS', 'zip']"
### Expected behavior
`the_pile` dataset should be dowloaded.
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-4.15.0-112-generic-x86_64-with-glibc2.27
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
|
CLOSED
| 2022-12-20T12:40:14
| 2023-02-15T16:24:57
| 2023-02-15T16:24:57
|
https://github.com/huggingface/datasets/issues/5381
|
LeoGrin
| 1
|
[] |
5,380
|
Improve dataset `.skip()` speed in streaming mode
|
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT it should speed up the skipping process.
### Motivation
When resuming from a checkpoint after a crashed run, using `dataset.skip()` is very convenient to recover the exact state of the data and to not train again over the same examples (assuming same seed, no shuffling). However, I have noticed that for audio datasets in streaming mode this is very costly in terms of time, as shards need to be downloaded every time before skipping the right number of examples.
### Your contribution
I took a look already at the code, but it seems a change like this is way deeper than I am able to manage, as it touches the library in several parts. I could give it a try but might need some guidance on the internals.
|
OPEN
| 2022-12-20T11:25:23
| 2025-11-10T20:05:37
| null |
https://github.com/huggingface/datasets/issues/5380
|
versae
| 11
|
[
"enhancement",
"good second issue"
] |
5,378
|
The dataset "the_pile", subset "enron_emails" , load_dataset() failure
|
### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset("the_pile","enron_emails")
### Expected behavior
Load dataset "the_pile", "enron_emails" successfully.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.7.1
- Platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.0
- Pandas version: 1.4.3
|
CLOSED
| 2022-12-20T02:19:13
| 2022-12-20T07:52:54
| 2022-12-20T07:52:54
|
https://github.com/huggingface/datasets/issues/5378
|
shaoyuta
| 1
|
[] |
5,374
|
Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
|
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/huggingface/datasets/pull/3050
### Steps to reproduce the bug
Running
```python
c4 = datasets.load_dataset("c4", "en", split="train", streaming=True).skip(args.start).take(args.end-args.start)
df = pd.DataFrame(c4, index=None)
```
with different start & end arguments on 200 CPUs in parallel yields:
```
WARNING:datasets.load:Using the latest cached version of the module from /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/df532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01 (last modified on Mon Dec 12 10:45:02 2022) since it couldn't be found locally at c4.
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [1/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [2/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [3/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [4/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [5/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [6/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [7/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [8/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [9/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [10/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [11/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [12/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [13/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [14/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [15/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [16/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [17/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [18/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [19/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [20/20]
╭───────────────────── Traceback (most recent call last) ──────────────────────╮
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/dec-2022-tasky/inference │
│ _c4.py:68 in <module> │
│ │
│ 65 │ model.eval() │
│ 66 │ │
│ 67 │ c4 = datasets.load_dataset("c4", "en", split="train", streaming=Tru │
│ ❱ 68 │ df = pd.DataFrame(c4, index=None) │
│ 69 │ texts = df["text"].to_list() │
│ 70 │ preds = batch_inference(texts, batch_size=args.batch_size) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/site-packages/pandas/core/frame.p │
│ y:684 in __init__ │
│ │
│ 681 │ │ # For data is list-like, or Iterable (will consume into list │
│ 682 │ │ elif is_list_like(data): │
│ 683 │ │ │ if not isinstance(data, (abc.Sequence, ExtensionArray)): │
│ ❱ 684 │ │ │ │ data = list(data) │
│ 685 │ │ │ if len(data) > 0: │
│ 686 │ │ │ │ if is_dataclass(data[0]): │
│ 687 │ │ │ │ │ data = dataclasses_to_dicts(data) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:751 in __iter__ │
│ │
│ 748 │ │ yield from ex_iterable.shard_data_sources(shard_idx) │
│ 749 │ │
│ 750 │ def __iter__(self): │
│ ❱ 751 │ │ for key, example in self._iter(): │
│ 752 │ │ │ if self.features: │
│ 753 │ │ │ │ # `IterableDataset` automatically fills missing colum │
│ 754 │ │ │ │ # This is done with `_apply_feature_types`. │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:741 in _iter │
│ │
│ 738 │ │ │ ex_iterable = self._ex_iterable.shuffle_data_sources(self │
│ 739 │ │ else: │
│ 740 │ │ │ ex_iterable = self._ex_iterable │
│ ❱ 741 │ │ yield from ex_iterable │
│ 742 │ │
│ 743 │ def _iter_shard(self, shard_idx: int): │
│ 744 │ │ if self._shuffling: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:617 in __iter__ │
│ │
│ 614 │ │ self.n = n │
│ 615 │ │
│ 616 │ def __iter__(self): │
│ ❱ 617 │ │ yield from islice(self.ex_iterable, self.n) │
│ 618 │ │
│ 619 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 620 │ │ """Doesn't shuffle the wrapped examples iterable since it wou │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:594 in __iter__ │
│ │
│ 591 │ │
│ 592 │ def __iter__(self): │
│ 593 │ │ #ex_iterator = iter(self.ex_iterable) │
│ ❱ 594 │ │ yield from islice(self.ex_iterable, self.n, None) │
│ 595 │ │ #for _ in range(self.n): │
│ 596 │ │ # next(ex_iterator) │
│ 597 │ │ #yield from islice(ex_iterator, self.n, None) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:106 in __iter__ │
│ │
│ 103 │ │ self.kwargs = kwargs │
│ 104 │ │
│ 105 │ def __iter__(self): │
│ ❱ 106 │ │ yield from self.generate_examples_fn(**self.kwargs) │
│ 107 │ │
│ 108 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 109 │ │ return ShardShuffledExamplesIterable(self.generate_examples_f │
│ │
│ /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/d │
│ f532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01/c4.py:89 in │
│ _generate_examples │
│ │
│ 86 │ │ for filepath in filepaths: │
│ 87 │ │ │ logger.info("generating examples from = %s", filepath) │
│ 88 │ │ │ with gzip.open(open(filepath, "rb"), "rt", encoding="utf-8" │
│ ❱ 89 │ │ │ │ for line in f: │
│ 90 │ │ │ │ │ if line: │
│ 91 │ │ │ │ │ │ example = json.loads(line) │
│ 92 │ │ │ │ │ │ yield id_, example │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:313 in read1 │
│ │
│ 310 │ │ │
│ 311 │ │ if size < 0: │
│ 312 │ │ │ size = io.DEFAULT_BUFFER_SIZE │
│ ❱ 313 │ │ return self._buffer.read1(size) │
│ 314 │ │
│ 315 │ def peek(self, n): │
│ 316 │ │ self._check_not_closed() │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/_compression.py:68 in readinto │
│ │
│ 65 │ │
│ 66 │ def readinto(self, b): │
│ 67 │ │ with memoryview(b) as view, view.cast("B") as byte_view: │
│ ❱ 68 │ │ │ data = self.read(len(byte_view)) │
│ 69 │ │ │ byte_view[:len(data)] = data │
│ 70 │ │ return len(data) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:493 in read │
│ │
│ 490 │ │ │ │ self._new_member = False │
│ 491 │ │ │ │
│ 492 │ │ │ # Read a chunk of data from the file │
│ ❱ 493 │ │ │ buf = self._fp.read(io.DEFAULT_BUFFER_SIZE) │
│ 494 │ │ │ │
│ 495 │ │ │ uncompress = self._decompressor.decompress(buf, size) │
│ 496 │ │ │ if self._decompressor.unconsumed_tail != b"": │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:96 in read │
│ │
│ 93 │ │ │ read = self._read │
│ 94 │ │ │ self._read = None │
│ 95 │ │ │ return self._buffer[read:] + \ │
│ ❱ 96 │ │ │ │ self.file.read(size-self._length+read) │
│ 97 │ │
│ 98 │ def prepend(self, prepend=b''): │
│ 99 │ │ if self._read is None: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/download/streaming_download_manager.py: │
│ 365 in read_with_retries │
│ │
│ 362 │ │ │ │ ) │
│ 363 │ │ │ │ time.sleep(config.STREAMING_READ_RETRY_INTERVAL) │
│ 364 │ │ else: │
│ ❱ 365 │ │ │ raise ConnectionError("Server Disconnected") │
│ 366 │ │ return out │
│ 367 │ │
│ 368 │ file_obj.read = read_with_retries │
╰──────────────────────────────────────────────────────────────────────────────╯
ConnectionError: Server Disconnected
```
### Expected behavior
There should be no disconnect I think.
### Environment info
```
datasets=2.7.0
Python 3.9.12
```
|
CLOSED
| 2022-12-18T11:38:58
| 2023-07-24T15:23:07
| 2023-07-24T15:23:07
|
https://github.com/huggingface/datasets/issues/5374
|
Muennighoff
| 7
|
[] |
5,371
|
Add a robustness benchmark dataset for vision
|
### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also correlated to the robustness aspects of vision models.
Researchers use different benchmark datasets to evaluate the robustness aspects of vision models. ImageNet-C is one of them.
Having this dataset in 🤗 Datasets would allow researchers to evaluate and study the robustness aspects of vision models. Since the metric associated with these evaluations is top-1 accuracy, researchers should be able to easily take advantage of the evaluation benchmarks on the Hub and perform comprehensive reporting.
ImageNet-C is a large dataset. Once it's in, it can act as a reference and we can also reach out to the authors of the other robustness benchmark datasets in vision, such as ObjectNet, WILDS, Metashift, etc. These datasets cater to different aspects. For example, ObjectNet is related to assessing how well a model performs under sub-population shifts.
Related thread: https://huggingface.slack.com/archives/C036H4A5U8Z/p1669994598060499
|
OPEN
| 2022-12-17T12:35:13
| 2022-12-20T06:21:41
| null |
https://github.com/huggingface/datasets/issues/5371
|
sayakpaul
| 1
|
[
"dataset request"
] |
5,363
|
Dataset.from_generator() crashes on simple example
|
CLOSED
| 2022-12-15T10:21:28
| 2022-12-15T11:51:33
| 2022-12-15T11:51:33
|
https://github.com/huggingface/datasets/issues/5363
|
villmow
| 0
|
[] |
|
5,362
|
Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' )
|
### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to reproduce the bug
Steps to reproduce this issue:
git clone https://github.com/huggingface/transformers
cd transformers
python examples/pytorch/language-modeling/run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --dataset_name the_pile --dataset_config_name enron_emails --do_eval --output_dir /tmp/output --overwrite_output_dir
### Expected behavior
This issue looks like due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst " couldn't be reached.
Is there another way to download the dataset "the_pile" ?
Is there another way to cache the dataset "the_pile" but not let the hg to download it when runtime ?
### Environment info
huggingface_hub version: 0.11.1
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Python version: 3.9.12
Running in iPython ?: No
Running in notebook ?: No
Running in Google Colab ?: No
Token path ?: /home/taosy/.huggingface/token
Has saved token ?: False
Configured git credential helpers:
FastAI: N/A
Tensorflow: N/A
Torch: N/A
Jinja2: N/A
Graphviz: N/A
Pydot: N/A
|
CLOSED
| 2022-12-15T01:23:03
| 2022-12-15T07:45:54
| 2022-12-15T07:45:53
|
https://github.com/huggingface/datasets/issues/5362
|
shaoyuta
| 2
|
[] |
5,361
|
How concatenate `Audio` elements using batch mapping
|
### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batch), 3)
dataset = dataset.map(mapper_function, batch=True, batch_size=24)
print(dataset)
# Expected output:
# Dataset({
# features: ['path', 'audio'],
# num_rows: 8
# })
```
I tried to construct `result={}` dictionary inside the mapper function, I just found it will not work because it needs `byte` also needed :((
I'd appreciate if your share any use cases similar to my problem or any solutions really. Thanks!
cc: @lhoestq
### Steps to reproduce the bug
1. load audio dataset
2. try to merge every k audios and return as one
### Expected behavior
Merged dataset with a fewer rows. If we merge every 3 rows, then `n // 3` number of examples.
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
|
CLOSED
| 2022-12-14T18:13:55
| 2023-07-21T14:30:51
| 2023-07-21T14:30:51
|
https://github.com/huggingface/datasets/issues/5361
|
bayartsogt-ya
| 3
|
[] |
5,360
|
IterableDataset returns duplicated data using PyTorch DDP
|
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()`
|
CLOSED
| 2022-12-14T16:06:19
| 2023-06-15T09:51:13
| 2023-01-16T13:33:33
|
https://github.com/huggingface/datasets/issues/5360
|
lhoestq
| 11
|
[] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.